Process dataframes
Each script should specify its' input and output parameters. Datagrok automatically injects input parameters' values before the script starts and captures output parameters' values when the script finishes.
Datagrok natively supports standard scalar data types:
int, double, bool, string.
For table data, Datagrok supports Dataframe as input/output parameters.
You can pass to the script the whole dataframe (dataframe type), dataframe column (column), list of columns (column_list),
or a binary file (file, blob).
Datagrok's dataframe converts to:
- Pandas dataframe for Python,
- Native data frames for R,
- Cell arrays for Octave
- DataFrame for Julia
- DG.DataFrame for JavaScript
Let's modify the default example to accept and return both dataframes and scalars. We copy the original dataframe and add a new ID column to it. Also, we return the number of rows in the table.
- Result
- R
- Python
- JavaScript
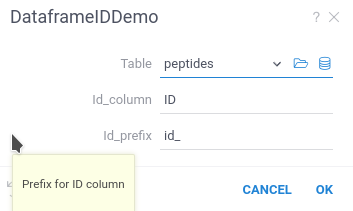
When you run the script, you will see the following dialog:
#name: DataframeDemo
#description: Adding a new column to a dataframe
#language: r
#tags: demo, dataframe
#input: dataframe table [Data table]
#input: string id_column = 'ID' [Name of ID column]
#input: string id_prefix = 'id_' [Prefix for ID column]
#output: dataframe new_table [New table with additional column]
#output: int last_row [number of last row]
new_table <- table
new_table[id_column] <- paste0(id_prefix, 1:nrow(new_table))
last_row <- nrow(new_table)
#name: DataframeIdDemo
#description: Adding ID column to a dataframe
#language: python
#tags: demo, dataframe
#input: dataframe table [Data table]
#input: string id_column = 'ID' [Name of ID column]
#input: string id_prefix = 'id_' [Prefix for ID column]
#output: dataframe new_table [New table with additional column]
#output: int last_row [number of last row]
new_table = table.copy()
l = len(new_table)
new_table[id_column] = [f"{id_prefix}{n:04}" for n in range(l)]
last_row = len(new_table)
//name: DataframeIdDemo
//description: Adding ID column to a dataframe
//language: javascript
//tags: demo, dataframe
//sample: cars.csv
//input: dataframe table [Data table]
//input: string id_column = 'model' [Name of ID column]
//input: string id_prefix = 'id_' [Prefix for ID column]
//output: dataframe new_table [New table with additional column]
//output: int last_row [number of last row]
const new_table = table.clone();
const last_row = new_table.rowCount;
new_table.col(id_column).init((i) => `${id_prefix}${i}`);
Datagrok created the script UI, populated default values, and created popups with help text.
After running this script, Datagrok automatically opens the new dataframe. It will contain an additional column ID with the generated row ID.
In Datagrok, unlike Python/R dataframes, column names are case-insensitive.
If you return a dataframe with columns whose names differ only by letter case,
Datagrok will automatically add a number to the column header to differentiate them.
To prevent any confusion or issues with column names, we recommend using unique names that are distinct regardless of case.