Function annotations
There are various types of functions, such as scripts or queries. All of them are annotated in a similar way, and that enables universal support for functions in the platform.
A function annotation, also known as a header, is a multi-line comment that is placed above the function declaration. It contains information about the function name, role, as well as function inputs and outputs. Inputs and outputs can have metadata associated with them as well.
When you run a function, Datagrok generates the UI from the parameter annotations. You can build interactive experiences that allow validation, controlled vocabularies, autocomplete, custom inputs, dynamic lookups, referencing parameters, and function chaining - without writing a single line of UI code!
Function
There are general parameters common to all functions, as well as parameters specific to certain function types. Not all general parameters are required, the list of parameters depends on the function type, role, and so on.
Simple python script
#language: python
#name: GetCellNumber
#description: Calculates number of cells in the table
#tags: demo
#input: dataframe table [Data table]
#output: int count [Number of cells in table]
count = table.shape[0] * table.shape[1]
These are the common parameters for all functions:
name: shows up in the user interfacedescription: shows up in a function tooltiptags: comma-separated tags that you can use in searchhelp-url: help that shows up when you click on the "?" in the function dialogreference: Reference to a research paper, Wikipedia article, Git repository, etc.top-menu: Top menu path separated with pipes (|), such asChem | Gasteiger Charges
Some parameters are specific to script language and/or technology:
- Script
language: script language (supported:r,python,octave,julia,grok,javascript)environment: script environment (Conda environment for python, etc)sample: path to a sample data csv file. When defined, a*icon appears on the ribbon panel that loads it.
- Script-based info panels
condition: GrokScript condition that gets evaluated to decide whether to show the panel for the object
- Query
connection: Name of the db connection that the query should use
- Scheduling (server-based functions only)
schedule: Cron expression for automatic execution (e.g.,0 8 * * *for daily at 8am)schedule.runAs: Group or role for execution context. You must be a member of the specified group. See Scheduling.
To add additional parameters, use the meta. prefix. They can be used for dynamically searching for
the functions of interest.
Inputs and outputs
Each input and output definition takes one line, starting with a comment, followed by type, name, optional initial value used to pre-fill the UI, options, and optional description, just like here:
#input: string country {choices: ["USA", "Canada"]} [Country to ship from]
#input: double weight
#output: double price
There is a crucial difference between annotation of scrips and Javascript functions in packages. When you annotate a script in any supported language, parameters are mapped by the parameter name. So the parameter name and value always are consistent.
When you annotate a Javascript function from a package, parameters are mapped by parameter order instead of name. Let's explore it on the following example:
//name: ParameterTestFunction
//description: Small function to illustrate parameter mapping
//language: javascript
//input: int one=1 {caption: First} [First parameter]
//input: int two=2 {caption: Second} [Second parameter]
export function ParameterTestFunctionPkg(two, one) {
const result = `First:${one}, second:${two}`;
console.log(result);
}
In the function signature, the parameter names go in the different order: (two, one),
comparing to the annotation.
As a result, the function will produce the unexpected result: First:2, second:1
To avoid mistakes, we suggest that you always use exactly the same parameter order in the function annotation and the function signature.
Parameter types and options
Datagrok supports the following types in all scripting languages:
- Scalars:
int,double,bool,string,datetime - Table:
dataframe,column,column_list - Collections:
list(typically of strings) graphics: typically a function output. See examplefile: when the script is executed, contains a string with the path to a fileblob: array of bytes
For the native equivalent of each type in Python, R, Octave, Julia, and JavaScript, see Data types.
Some of the options apply to all parameters, while other are type-specific.
Reference: list of options applicable to different parameters
For all parameters:
| Option | Value | Description |
|---|---|---|
| validator | string | Single validator: a Grok expression or a regex literal |
| validators | string | Comma-separated list of validators |
| caption | string | Custom field caption |
| postfix | string | Field postfix |
| units | string | Value unit name |
| nullable | bool | Makes it an optional parameter |
| category | string | Groups the parameter under a named section in the function dialog. See parameter groups. |
For dataframe type:
| Option | Value | Description |
|---|---|---|
| columns | numerical | Only numerical columns will be loaded |
| columns | categorical | Only categorical columns will be loaded |
For column and column_list types
| Option | Value | Description |
|---|---|---|
| type | numerical,categorical,dateTime | In a dialog, only numerical columns will be shown |
| format | MM/dd/yyyy | Datetime format, for dateTime columns and datetime type only |
| allowNulls | true/false | Adds validation of the missing values presence |
| action | join("table parameter name") | Joins result to the specified table, for output parameters only |
| action | replace("table parameter name") | Replaces result with columns in specified table, for output parameters only |
For string type
| Option | Value | Description |
|---|---|---|
| choices | Comma-separated list of values, or a function name that returns a list of strings | Makes it a combo box |
| suggestions | Name of a function that returns a list of strings to autocomplete user input | Autocomplete gives you options as you type |
For numeric types
| Option | Description |
|---|---|
| min, max | Minimum and maximum to be validated. When both are defined, slider is added for the float input, and +/- clicker is added to the int input |
For list type`
| Option | Value |
|---|---|
| separators | Characters used to split string to list of values. Default is , |
Separators apply only for the TextArea input type. The following example demonstrates how separators work for the Postgres-based SQL query:
Example: Using separators in a query
--name: OrdersByEmployee
--friendlyName: OrdersByEmployee
--connection: PostgresNorthwind
--input: string shipCountry = "Spain" {choices: Query("SELECT DISTINCT shipCountry FROM orders")}
--input: string shipCity = "Barcelona" {choices: Query("SELECT DISTINCT shipcity FROM orders WHERE shipCountry = @shipCountry")}
--input: string customerId = "GALED" {choices: Query("SELECT DISTINCT customerid FROM orders WHERE shipCity = @shipCity")}
--input: list<string> employee {inputType: TextArea; separators: ,}
SELECT *
FROM orders
INNER JOIN employees
ON orders.employeeId = employees.employeeId
WHERE lastName in (SELECT unnest(@employee))

Parameter groups
Use category to group related parameters under a shared section header in the function dialog:
//input: double learningRate {category: Hyperparameters}
//input: double momentum {category: Hyperparameters}
//input: int epochs {category: Training}
For functions with many parameter groups, use meta.categoryGroups to organize categories into a
hierarchy of collapsible sections. The value is a JSON object where keys are section headers and
values are lists of category names:
//meta.categoryGroups: {"Model": ["Input Data", "Architecture"], "Training": ["Hyperparameters", "Optimizer"]}
//input: dataframe data {category: Input Data}
//input: int layers {category: Architecture}
//input: double learningRate {category: Hyperparameters}
//input: string optimizer {category: Optimizer}
This renders as:
▸ Model
▸ Input Data
data
▸ Architecture
layers
▸ Training
▸ Hyperparameters
learningRate
▸ Optimizer
optimizer
A group header category can also contain direct inputs alongside sub-groups. Assign an input the same category name as the group header, and it appears directly under that header before any sub-groups:
//meta.categoryGroups: {"All Params": ["Group A", "Group B"]}
//input: double a {category: Group A}
//input: double b {category: Group A}
//input: double c {category: Group B}
//input: double d {category: Group B}
//input: double e {category: All Params}
▸ All Params
e
▸ Group A
a, b
▸ Group B
c, d
When all parameters in a category are hidden programmatically (via input.visible = false),
the category header hides automatically. If all sub-categories under a section header are also
hidden, that header hides too.
Output parameter groups
Use meta.outputCategoryGroups to organize scalar output categories into super-categories.
The format mirrors meta.categoryGroups but applies only to scalar outputs rendered by
Compute2's Rich Function View. DataFrame and viewer outputs are unaffected; the annotation
is deliberately separate so the two can coexist on the same function.
//output: double rmse {category: Metrics}
//output: double r2 {category: Metrics}
//output: double trainTime {category: Performance}
//meta.outputCategoryGroups: {"Summary": ["Metrics", "Performance"]}
Each top-level key produces one scalar-output tab; nested {label: [...]} entries appear
as indented sub-sections inside that tab. Referenced categories that don't exist, or that
contain non-scalar outputs, are silently skipped — their original tabs are left in place.
Initial values and optional parameters
Proper handling of the empty parameters requires special efforts when building a SQL query, and passing empty parameters to the function that does not expect it is a major source of errors. To deal with it, by default each parameter is required, but you can specify initial values and make it optional (nullable).
- Initial value gets shown in the dialog when you execute the function. If you remove the value, an empty value is passed to the function. But before the function is executed, the input is validated, and you will get an error if a required parameter is not specified.
- Optional parameter: make a parameter optional by specifying the
nullable: trueoption.
For example, to create an optional string parameter with the initial value:
--input: string shipCountry = "France" { nullable: true }
SELECT * FROM customers where shipCountry = @shipCountry
Nullable vs Optional
It’s important to distinguish between nullable and optional parameters:
- Nullable parameters can explicitly accept
null, but are still required positional parameters. You must pass them in the function call, even if the value isnull.
Func(1, null, 3)
- Optional parameters are named parameters with default values and can be skipped entirely in function calls.
Func(1, 3, optional = 4)
In the UI forms, both nullable and optional parameters appear similarly (users can leave the field empty), but their behavior in code differs.
Filter patterns
Filter pattern allows you to use free-text conditions like "this week" for dates, or ">50" for numbers.
To use search patterns, set the input type to string, and set the pattern option
to the type of the column you are filtering. Then, reference the pattern in the query
as @patternName(columnName), just like we did here for the "freight" column:
--input: string freightValue = >= 10.0 {pattern: double}
select * from Orders where @freightValue(freight)
Different inputs would produce differently structured SQL (also dependent on the database).
| Input | SQL | Description |
|---|---|---|
| select * from orders where 1 = 1 | No input => no filter | |
| >3 | select * from orders where freight > 3 | Using column name to filter |
| 10-20 | select * from orders where (freight >= 10 and freight <= 20) | Have to do multiple comparisons |
In this example, the freightValue input parameter is defined as a string with a default value of >= 10.0.
The pattern option specifies that the actual data type is a double. In the query, a reference to
@freightValue(freight) specifies the pattern that will be evaluated against the "freight" column.
Reference: Supported search patterns
| Type | Value | Description or example |
|---|---|---|
num, int, double | = | = 100 |
> | > 1.02 | |
>= | >= 4.1 | |
< | < 5 | |
<= | <= 2 | |
in | in (1, 3, 10.2) | |
min-max | Range: 1.5-10.0 | |
string | contains | contains ea |
starts with | starts with R | |
ends with | ends with w | |
regex | regex 1(\w+)1 | |
in | in (ab, "c d", "e\\"f\\"") | |
datetime | anytime | |
today | ||
this week | ||
this month | ||
this year | ||
yesterday | ||
last week | ||
last month | ||
last year | ||
before | before July 1984 | |
after | after March 2001 | |
min-max | Range: 1941-1945 |
To learn more, see search patterns.
Choices
Use choices to make input a combo box, and restrict the selection to the defined set of values.
You can define choices using a comma-separated list of values,
a CSV file,
a name of another function (such as query),
or by writing an actual SQL query.
Example: SQL query: single choice: different ways to specify a list of countries
--input: string shipCountry = "France" {choices: ['France', 'Italy', 'Germany']}
--input: string shipCountry = "France" {choices: Samples:countries}
--input: string shipCountry = "France" {choices: Query("SELECT DISTINCT shipCountry FROM Orders")}
--input: string shipCountry = "France" {choices: OpenFile("System:AppData/Samples/countries.csv")}
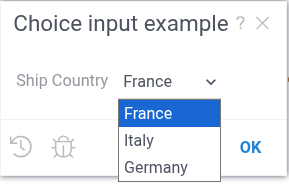
When you provide as input a multi-column CSV file, Datagrok uses the first column for the list of values.
Example: SQL query: multiple choice for the "list" input
When choices is applied to the list parameter, the input becomes a multiple choice, just like in
this example:
--input: list<string> company {choices: Query("SELECT DISTINCT company from research_companies")}
To specify initial values for a multiple choice, use a JavaScript array:
--input: list<string> shipCountries = ["France", "Germany"] {choices: ['France', 'Italy', 'Germany']}
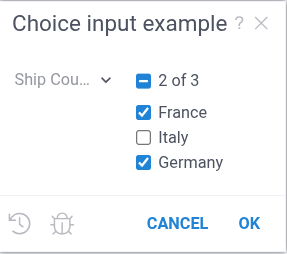
Multi-value choices are now supported only in JavaScript.
The multi-choice support for Python and R
is planned for the next releases.
Validation
In addition to the built-in checks that the value is not missing, and that it satisfies min-max conditions, you can specify custom validation functions that get executed before calling the function to assure the validity of the parameters.
The easiest way is to define a validator GrokScript expression that gets evaluated when input changes.
Result true or null means that the input is valid. false or a string error message means that the input is invalid,
it gets highlighted and the validation message is shown in the tooltip. Note that the expression can depend not only on the
value of the parameter the expression applied to, but on other parameters as well.
Inside the expression, value always refers to the current input's value, so the same validator can be reused across
parameters without rewriting the parameter name.
Example: Inline validation dependent on the value of other parameters
//input: int foo = 5 { validator: bar > 3 }
//input: double bar = 2 { min: 0; max: 10 }
//input: string code = "1234" { validator: startsWith(value, "12") }
The second option involves using a custom validation function and referencing it. A validation
function accepts one parameter (the value the user enters) and returns either null (valid) or
the reason it's invalid (a string). It can also return a boolean — true is valid, false
shows a generic message naming the function.
To reference a function from another package, prefix the name with the package: Pkg:FuncName.
Validators must be synchronous. Only package.ts exports and grok.functions.register({...})
qualify. Scripts (UI-saved or shipped under scripts/, any language) don't — they're async and
will throw at dialog open. For server-side validation, validate inside the function body and throw.
Example: Functions as validators
The following example adds a "containsLettersOnly" function to the "col" parameter:
#input: string s {validators: ["containslettersonly"]}
#input: column col {validators: ["containsmissingvalues"]}
//name: jsVal1
//input: string s
//output: string valid
valid = input < 11 ? null : "Error val1";
#name: Numbers
#language: python
#input: int count1 {validators: ["jsval1"]
Cross-package, bool-returning predicates work directly:
//input: string smiles = "CCO" {validators: ["Chem:isSmiles"]}
//input: string smarts = "[#6]" {validators: ["Chem:isSmarts"]}

The third option is a regex literal in JavaScript form /pattern/flags. The input is valid when
the value matches the pattern. Supported flags are i (case-insensitive) and m (multi-line).
Example: Regex validator
//input: string code = "1234" {validator: /^[0-9]{4}$/}
//input: string country = "US" {validator: /^[A-Z]{2}$/i}
"Visible" and "enabled" expressions
You can control input's visibility and enabled state by specifying GrokScript expressions on the parameter level, similarly to validation. Note that the expression can depend not only on the value of the parameter the expression applied to, but on other parameters as well.
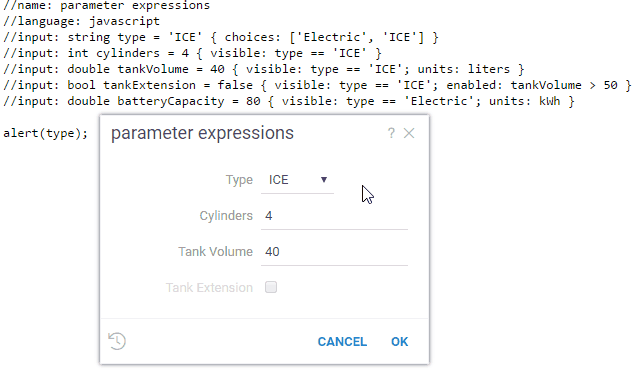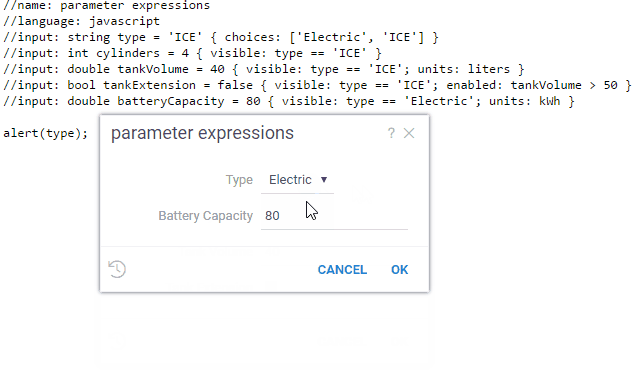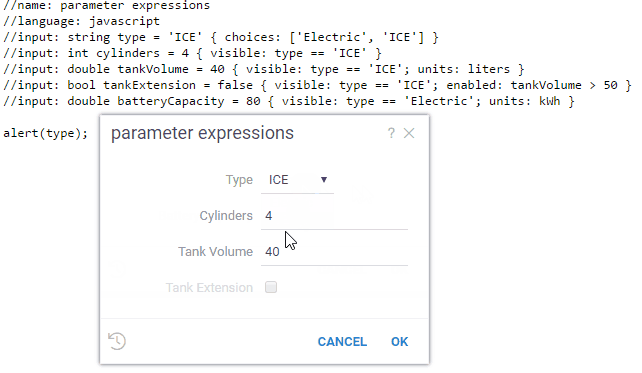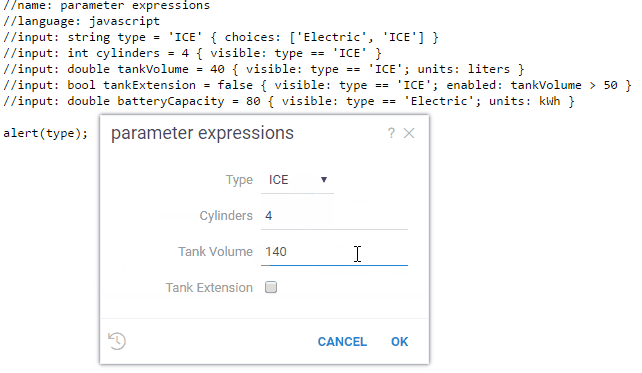
Example: input visibility and enabled state dependent on the value of other parameters
//input: string type = 'ICE' { choices: ['Electric', 'ICE'] }
//input: int cylinders = 4 { visible: type == 'ICE' }
//input: double tankVolume = 40 { visible: type == 'ICE'; units: liters }
//input: bool tankExtension = false { visible: type == 'ICE'; enabled: tankVolume > 50 }
//input: double batteryCapacity = 80 { visible: type == 'Electric'; units: kWh }
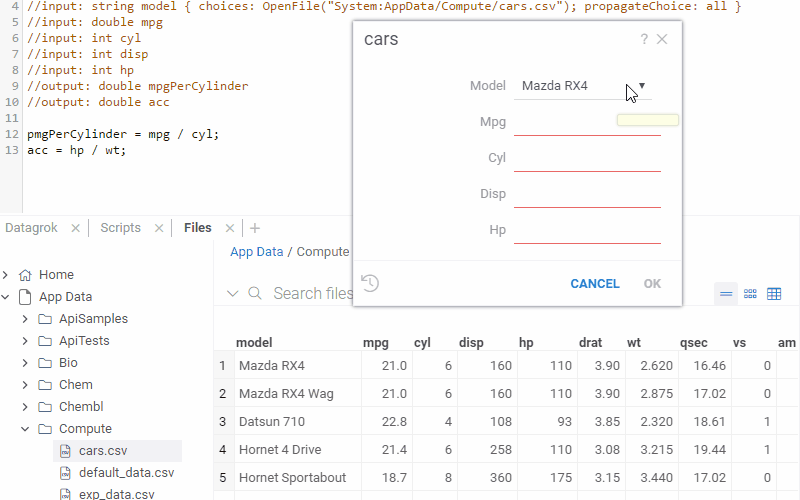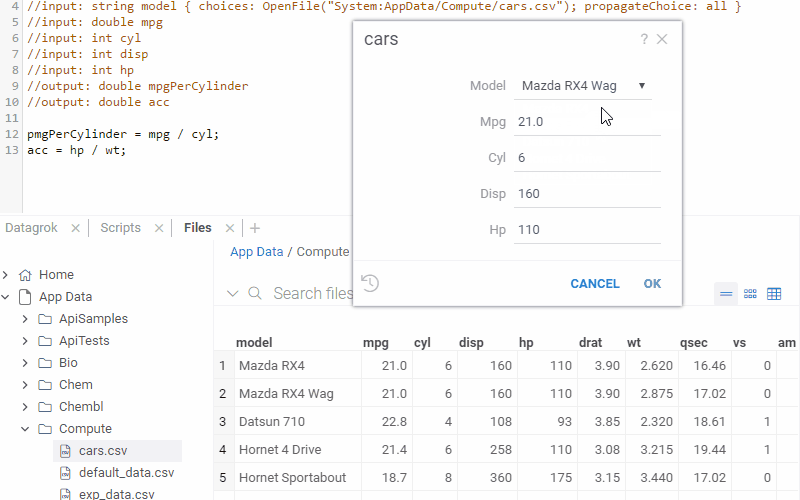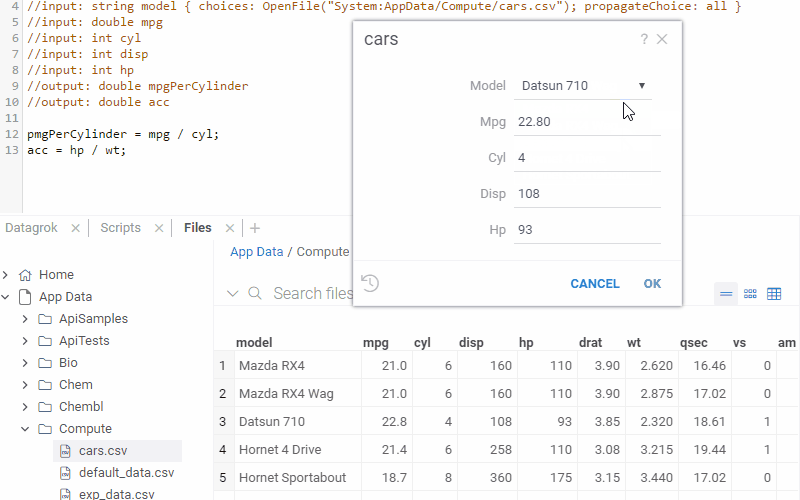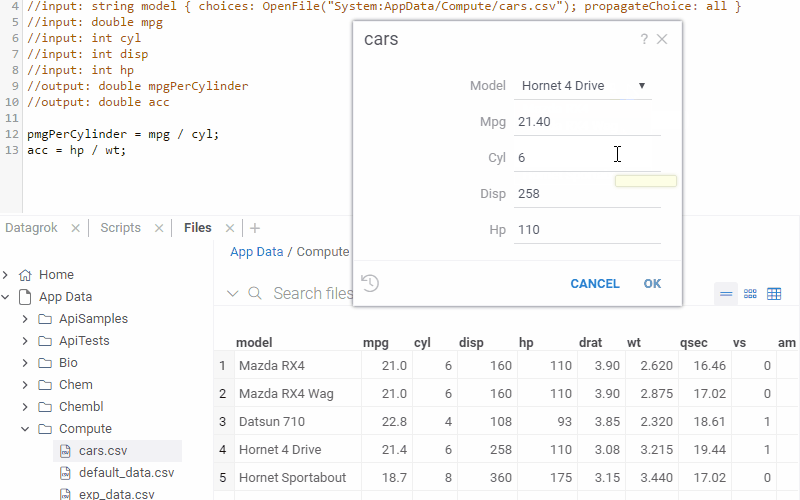
Lookup tables
Lookup tables let you initialize inputs with a set of pre-defined values. To use it, set
the choices attribute to a function that returns a dataframe, and set propagateChoice to "all".
The first column is used as a key in the combo box. When you select it, the input fields are initialized with the
values from the corresponding columns (input names and column names have to match).
Example: Lookup table
The following example lets you initialize multiple car's parameters based on the model that you select.
Note that here we use the OpenFile function to read a dataframe from the CSV file on a file share; it would
work the same if we read it from the database using the Query function.
//input: string model { choices: OpenFile("System:AppData/Compute/cars.csv"); propagateChoice: all }
//input: double mpg
//input: int cyl
//input: int disp
model,mpg,cyl,disp,hp,drat,wt,qsec,vs,am,gear,carb
Mazda RX4,21.0,6,160,110,3.90,2.620,16.46,0,1,4,4
Mazda RX4 Wag,21.0,6,160,110,3.90,2.875,17.02,0,1,4,4
Datsun 710,22.8,4,108,93,3.85,2.320,18.61,1,1,4,1
Hornet 4 Drive,21.4,6,258,110,3.08,3.215,19.44,1,0,3,1
Hornet Sportabout,18.7,8,360,175,3.15,3.440,17.02,0,0,3,2
Referencing other parameters
Parameter's choices, validators, and suggestions can depend on the value of another parameter.
This is useful when creating queries with hierarchical choices, where each subsequent parameter
depends on the previous one. To do this, reference the parameter in another parameter's annotation
using the @ symbol.
Example: SQL-based hierarchical query
Let's say we want to build a UI, where you first select a state and then choose a city from
the corresponding state. All we need to do is to reference the @state parameter in the query
that retrieves a list of cities:
--input: string state {choices: Query("SELECT DISTINCT state FROM public.starbucks_us")}
--input: string city {choices: Query("SELECT DISTINCT city FROM public.starbucks_us WHERE state = @state")}
SELECT * FROM public.starbucks_us WHERE (city = @city)
Datagrok does the rest, and turns it into an interactive experience:
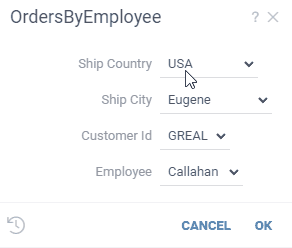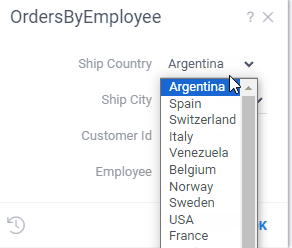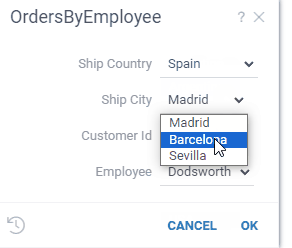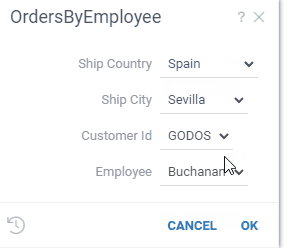
At the moment, parameter referencing is implemented only for SQL queries. The implementation for JavaScript and other languages is in progress.
Autocomplete
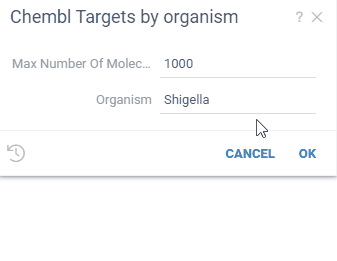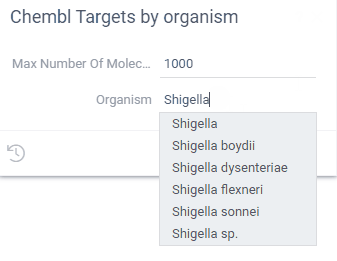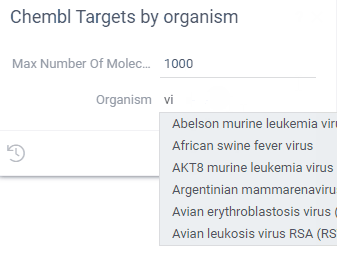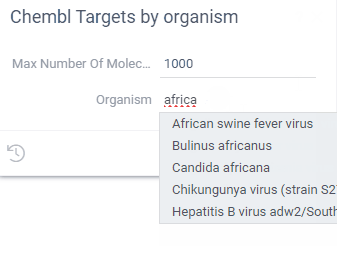
Use autocomplete to help users enter a correct value. For instance, when entering a product name, it might make sense to dynamically query a database for values starting with the already entered text, and suggest to auto-complete the value.
Use the suggestions option to enable autocomplete, and specify the name of a function that
accepts one string parameter, and returns a list of strings (or a dataframe with one string column)
to be used as suggestions as the user types the value.
Example: SQL-based autocomplete function
Here are two SQL functions (from the Chembl package), where the UI for the "Structures by Organism" query uses the "organismsAutocomplete" function to complete user input:
--name: organismsAutocomplete
--input: string sub
select distinct organism from target_dictionary
where organism ilike '%' || @sub || '%'
limit 50
--name: StructuresByOrganism
--input: string organism = "Shigella" {suggestions: Chembl:organismsAutocomplete}
SELECT md.chembl_id AS compound_chembl_id,
cs.canonical_smiles,
act.standard_type,
act.standard_value,
act.standard_units,
td.chembl_id AS target_chembl_id,
td.organism, td.pref_name
FROM target_dictionary td
JOIN assays a ON td.tid = a.tid
JOIN activities act ON a.assay_id = act.assay_id
JOIN molecule_dictionary md ON act.molregno = md.molregno
JOIN compound_structures cs ON md.molregno = cs.molregno
JOIN organism_class oc ON td.tax_id = oc.tax_id
AND td.organism = @organism
AND oc.L1 = 'Bacteria'
Function inputs
To reuse other "helper" functions along with their editors for your top-level function, specify
the helper function using the editor option. In the following example, we have a parameter orders
that points to the Samples:OrdersByEmployee function, so in the autogenerated UI, we see the inputs
of that function instead of the normal dataframe input. When the top-level function is executed,
orders parameters gets evaluated to the results of the execution of the Samples:OrdersByEmployee
function with the specified parameters.
To get the internal parameters of the orders function, you can specify them in the input using the
editorParam option. In the following example, we have a parameter country that points to the shipCountry
parameter of the orders function. When the top-level function is executed, country parameter gets evaluated
to the value of the orders.shipCountry parameter. That way, you can reference the internal parameters of the
helper function and use them in the top-level function.
This powerful technique allows to reuse functions, and mix multiple technologies and languages within one script. You can get your data with a SQL query, run calculations in Python, and then visualize it interactively in Datagrok - all of that without writing a single line of UI code. To learn more, see Compute.
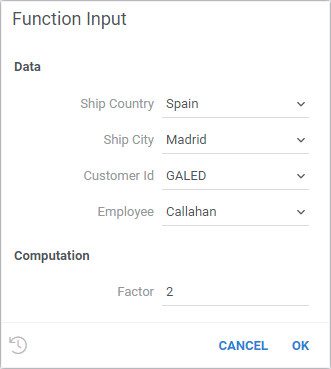
Example: JavaScript function that uses SQL query as a function input
//language: javascript
//input: dataframe orders {category: Data; editor: Samples:OrdersByEmployee}
//input: int factor = 2 {category: Computation}
//input: string country {category: Computation; editorParam: orders.shipCountry}
//output: string result
result = `${country} - ${orders.rowCount * factor}`;
Complex calculated columns
When you need to compute several related columns from the same data, complex calculated columns let you do it through a single function.
This approach improves both efficiency and user experience: instead of defining multiple separate calculated columns with nearly identical logic, you define one formula that returns several results at once. Each of these results becomes its own calculated column in the table.
This is particularly useful when several properties are derived from the same source data, for example:
- Computing multiple ADME properties (absorption, distribution, metabolism, excretion).
- Calculating chemical descriptors such as logP, TPSA, molecular weight, or others.
- Generating statistical summaries (mean, median, standard deviation, etc.) for related data columns.
Since all the derived columns are computed together, Datagrok can reuse cached computations, ensuring fast and consistent recalculation when input data changes.
How It Works
To define a complex calculated column function:
- Add the annotation
//meta.vectorFunc: true
- Make your function return a dataframe — each column in the returned dataframe becomes a calculated column in the source table.
- Optionally, add a
list<string>parameter to let users select which specific result columns to create (for instance, particular chemical properties or statistical measures). This parameter should be placed last in the function signature, since it’s optional.
Inputs can include both regular columns and scalar parameters.
Example: Computing chemical properties from the Chem package
//input: column molecules {semType: Molecule}
//input: list<string> out {optional: true}
//meta.vectorFunc: true
//output: dataframe result
export async function getProperties(molecules: DG.Column, out?: string[]): Promise<DG.DataFrame> {
const propNames = Object.keys(CHEM_PROP_MAP);
const props = !out || out.length === 0
? propNames
: propNames.filter((p) => out.includes(p));
const cols = await getPropertiesAsColumns(molecules, props);
return DG.DataFrame.fromColumns(cols);
}
This function calculates several chemical properties (such as logP, TPSA, or molecular weight) at once. Users can select which properties to generate, and each one will appear as a calculated column in the table.
Integration with “Add New Column”
You can use complex calculated column functions directly in the Add new column dialog — just type or insert such a function into the formula editor.
If the function has the meta.vectorFunc: true annotation, Datagrok automatically:
- Adds all resulting columns from the returned dataframe to your table.
- Keeps them synchronized and efficiently recalculated as data changes.
This allows you to create multiple derived columns (for example, several computed chemical descriptors) from one unified expression — all from the familiar Add new column interface.
Joining results to input tables
When a function computes new columns, you often want those results added directly to the source table rather than
returned separately. The action: join(tableName) annotation automates this — the function's output is automatically
joined to the specified input table parameter.
The annotation works with different output types:
column— a single computed column is added to the table.column_list— multiple columns are added to the table.dataframe— all columns from the returned dataframe are added to the table.
Example: Murcko scaffolds (Python)
The Murcko Scaffolds function from the Chem package extracts molecular scaffolds and joins them to the input table:
#name: Murcko Scaffolds
#description: Generation of Murcko scaffolds from a molecule
#input: dataframe data [Input data table]
#input: column smiles {type:categorical; semType: Molecule} [Molecules, in SMILES format]
#output: dataframe scaffolds {action:join(data); semType: Molecule} [Murcko scaffolds]
When this function runs, the resulting scaffolds column is automatically added to the data table.
Example: TypeScript with different output types
The annotation works with column, column_list, and dataframe outputs:
//name: addProcessedColumn
//input: dataframe data
//input: column col
//output: column res {action:join(data)}
export function addProcessedColumn(data: DG.DataFrame, col: DG.Column): DG.Column {
return DG.Column.string('processed', data.rowCount).init((i) => `${col.get(i)}_processed`);
}
TypeScript decorator syntax
Using decorators, you can specify the action in the outputs array:
@grok.decorators.func({
outputs: [{name: 'res', type: 'dataframe', options: {action: 'join(data)'}}],
})
static async getChemspacePrices(
data: DG.DataFrame,
@grok.decorators.param({type: 'column<string>', options: {semType: 'chemspace-id'}}) idsColumn: DG.Column,
shipToCountry: string
): Promise<DG.DataFrame> {
// Fetch prices and return as dataframe - columns are joined to data
}
Formula tagging and persistence
Columns joined via action: join behave like calculated columns:
- They are tagged with the formula that created them.
- When source data changes, they recalculate automatically.
- The formula is preserved in DataSync projects, ensuring reproducibility when reopening.
- Layouts containing these columns restore correctly when applied to new data.
Input types
Input fields such as text boxes or combo boxes get generated automatically based on
the property attributes. You can also explicitly set the inputType option. Here, we
set it to Radio to make the input appear as a radio button instead of the combo box:
//input: string fruit { choices: ["Apple", "Banana"], inputType: Radio }
Reference: Supported input types
Input types have to match the data types (input types in bold are the default ones that you do not have to specify):
| Input type | Data types | Example / description |
|---|---|---|
| Int | int | { min: 0; max: 20; step: 4} |
| BigInt | bigint | |
| Float | double | { min: 0; max: 1; step: 0.03 } |
| Bool | bool | |
| Text | string | |
| Date | datetime | |
| MultiChoice | list | { choices: ["A", "B"] } |
| List | list | { inputType: TextArea; separators: ,} |
| Column | column | |
| Slider | int, double | { min: 0; max: 20; step: 4} |
| Color | string | |
| Radio | string | {inputType: Radio; choices: ["A", "B"]} |
| Molecule | string |
Example: Using "Slider", "Color", and "Radio" input types
Check out interactive snippet for more input types.
For developers: DG.InputBase
Inputs for semantic types
Datagrok automatically detects semantic types, and you can also specify semantic types of input parameters. In this case, a corresponding input will be used, if it is defined.
Example: Automatically using the molecular sketcher for the "Molecule" semantic type
This is how an input field for the "Molecule" semantic type looks like. When you click a molecule, a molecule sketcher pops up.
--input: string substructure = 'c1ccccc1' {semType: Molecule}

Search integrated functions
Datagrok allows you to define a special patterns for calling any function or query with a human-readable sentence and visualize the resulting dashboard directly from the platform search.
When you create a function, script, or query that results in a table, you can annotate it with the meta.searchPattern tag. This tag will be used to call the function with the specified parameters within the sentence.
The searchPattern tag can be any sentence that contains placeholders for the parameters. For example, if the annotation of the query is as follows:
--input: string target = "CHEMBL1827"
--meta.searchPattern: "compound activity details for target ${target}"
Searching for "compound activity details for target CHEMBL1827" in the Search Everywhere bar will call the query and pass "CHEMBL1827" as the target parameter. The number of parameters is not limited, and they can be used in any order in the sentence.
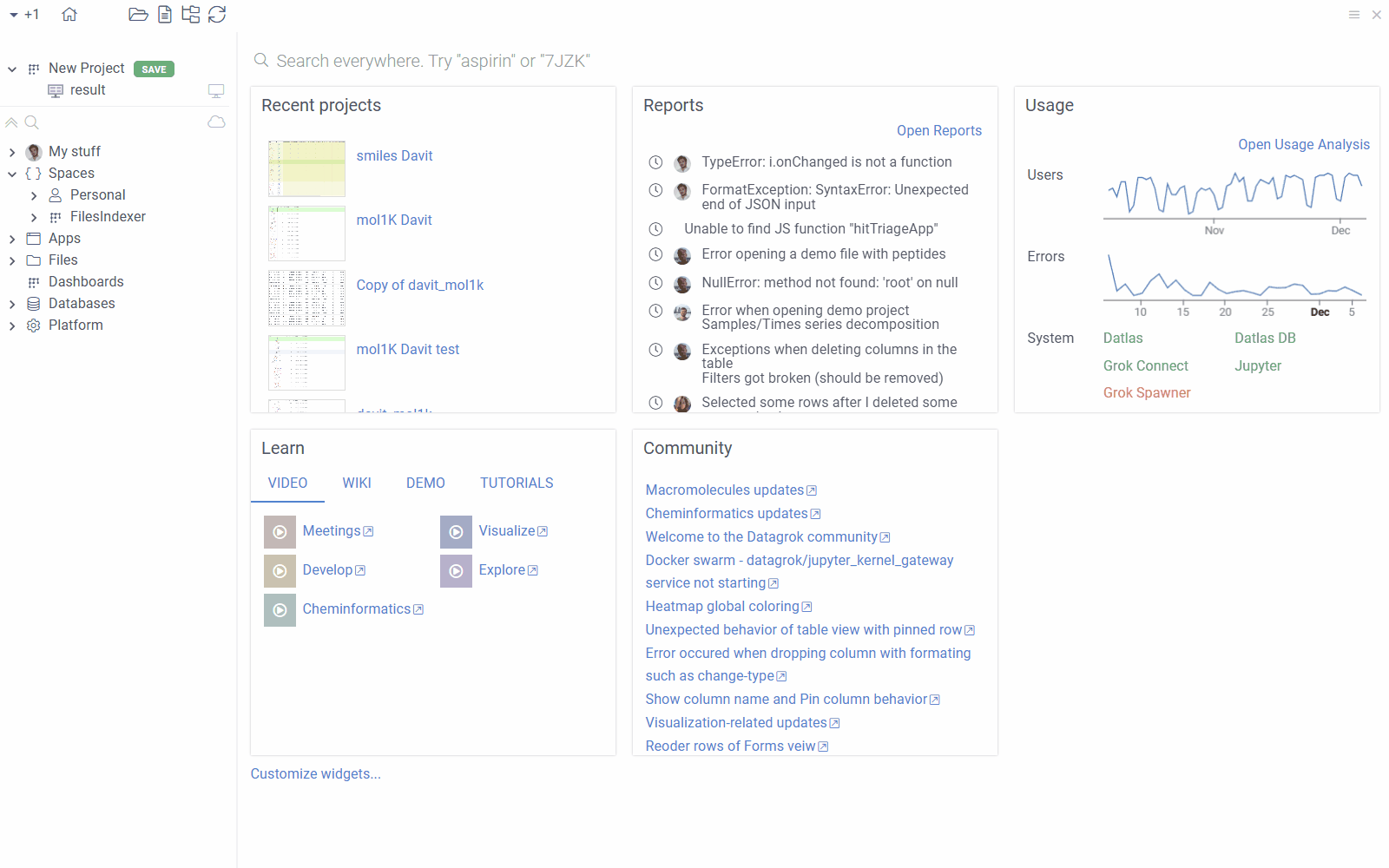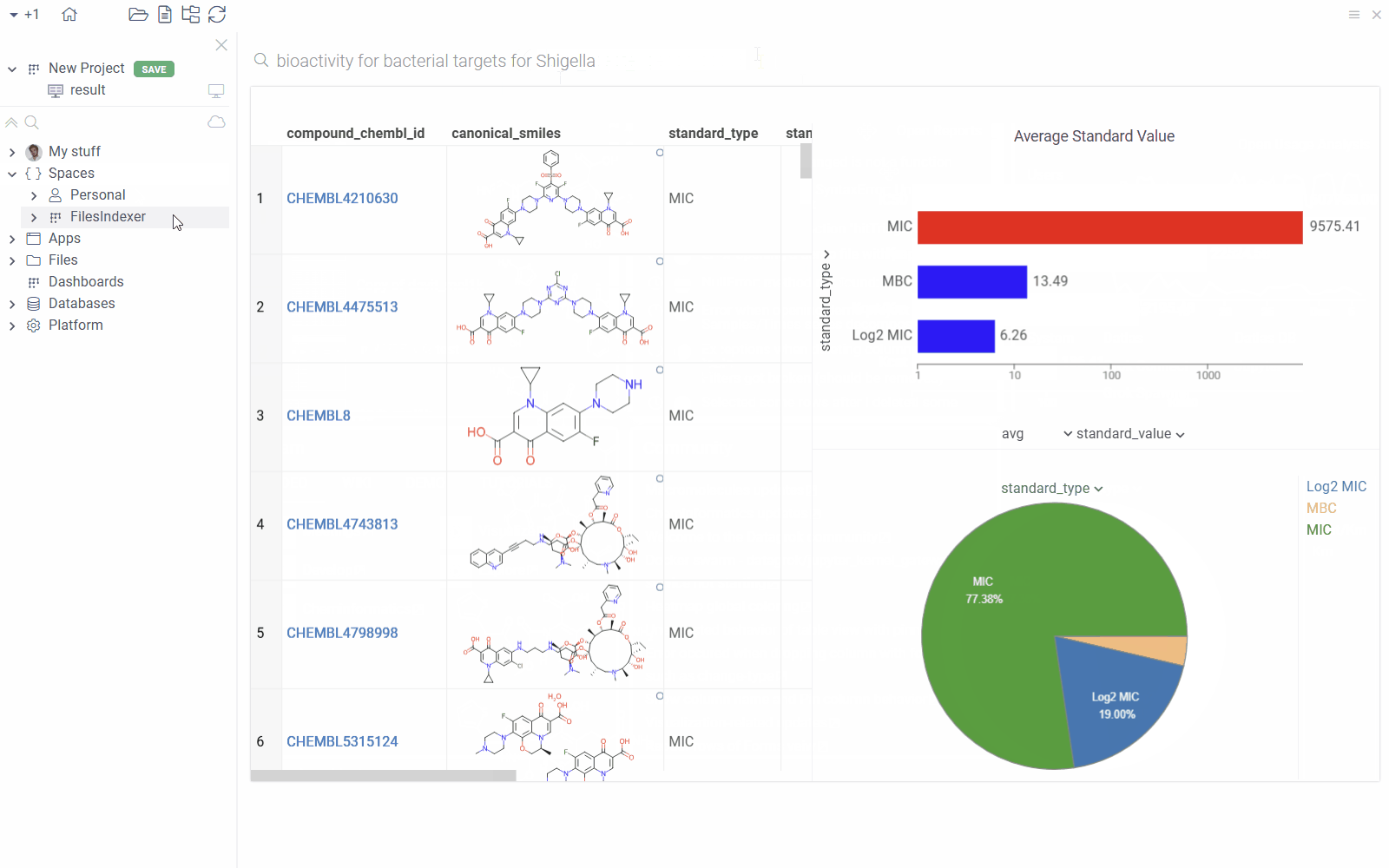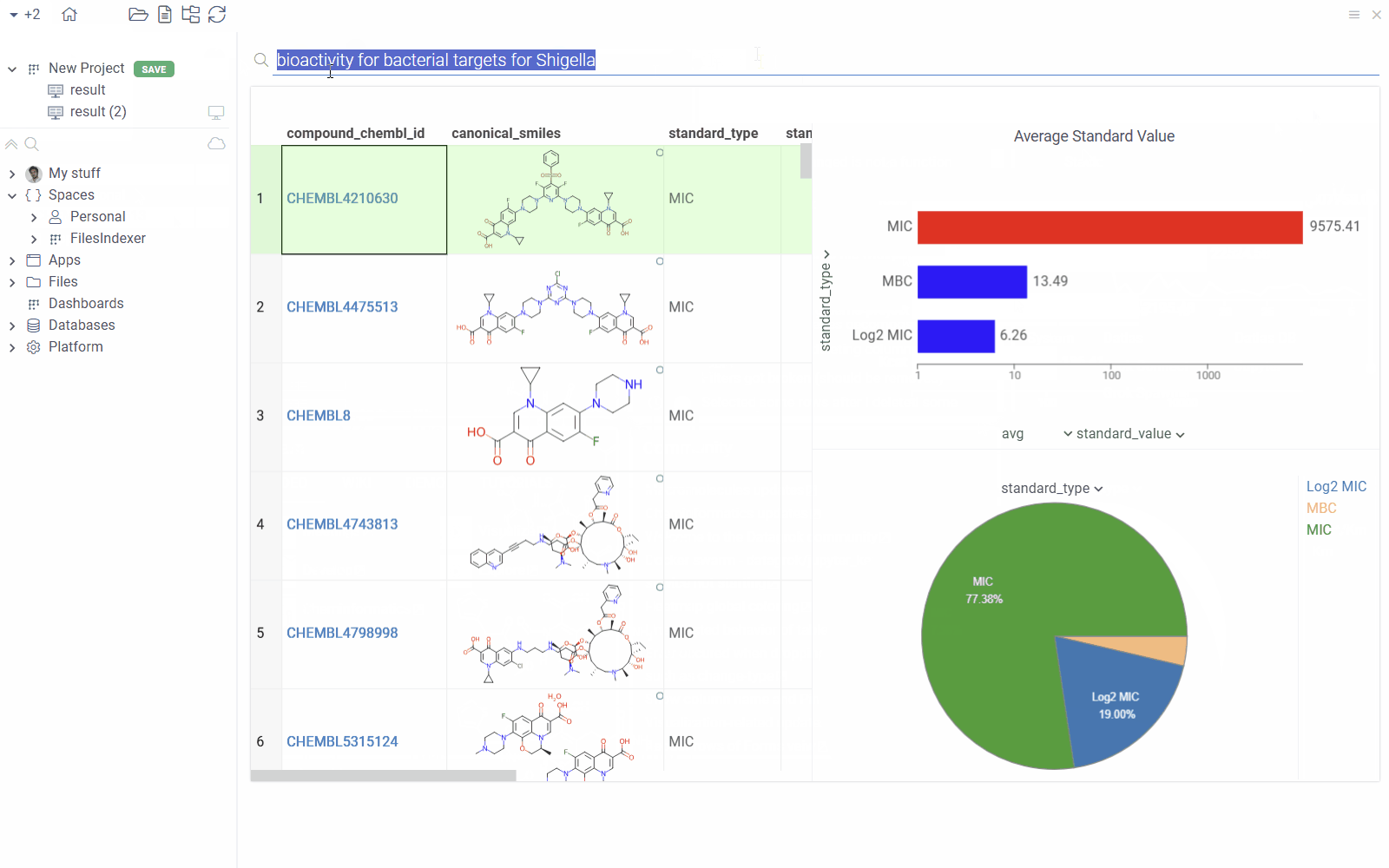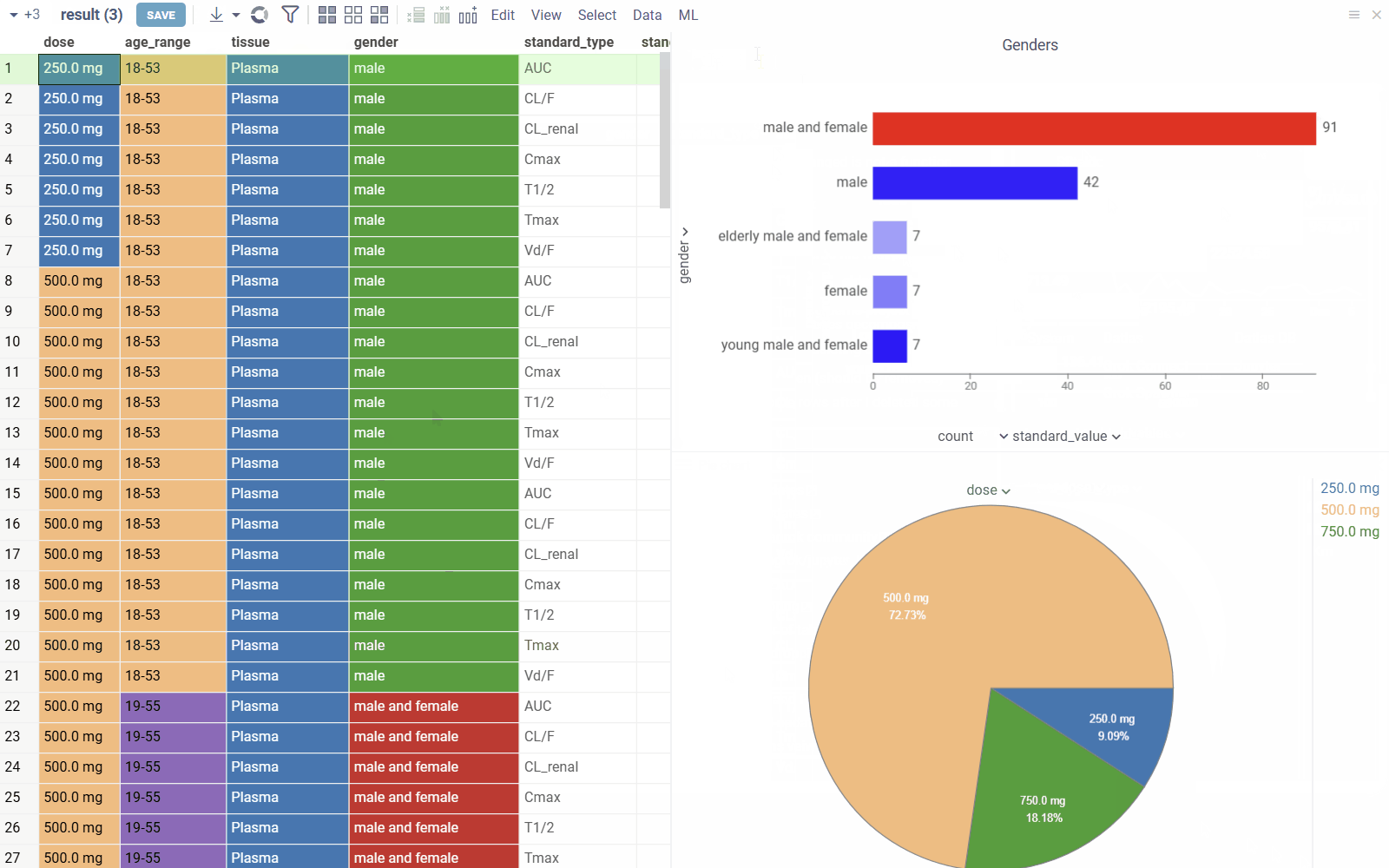
Use the Search Everywhere bar to visualize the following queries directly from the search results:
- Bioactivity for bacterial targets for Shigella
- Pharmacokinetic Data for LEVOFLOXACIN
- Compound activity details for target CHEMBL1827
You can also add the resulting dashboard to the workspace by clicking on the + icon in the search results.
Example query
--name: bioactivity data for bacterial targets for @organism
--friendlyName: Browse | Bioactivity for bacterial targets for @organism
--connection: Chembl
--input: string organism {suggestions: Chembl:organisms}
--input: string species
--meta.searchPattern: "Bioactivity for ${species} targets for ${organism}"
SELECT md.chembl_id AS compound_chembl_id,
cs.canonical_smiles,
act.standard_type,
act.standard_value,
act.standard_units,
td.chembl_id AS target_chembl_id,
td.organism, td.pref_name
FROM target_dictionary td
JOIN assays a ON td.tid = a.tid
JOIN activities act ON a.assay_id = act.assay_id
JOIN molecule_dictionary md ON act.molregno = md.molregno
JOIN compound_structures cs ON md.molregno = cs.molregno
JOIN organism_class oc ON td.tax_id = oc.tax_id
AND td.organism ILIKE @organism
AND oc.L1 = @species;
--end
Here, the species and organism parameters are inferred from the search pattern. For example, if you search for "Bioactivity for bacteria targets for Shigella", the species parameter will be set to "bacteria" and the organism parameter will be set to "shigella".
Custom function editors
You can create custom editors for functions to replace the default UI in places such as:
- Function preview
- Property panel
- "Run" dialog
Custom editors enhance the user experience by allowing you to tailor how function inputs are handled. For example, you can:
- Pre-fill values based on context
- Group related parameters together
- Add live validation of input formats
- Customize layout and interactivity
- Replace standard inputs with custom UI
⚠️ Important: Custom editors let you control how a function's parameters are presented and edited, and should be responsible only for editing parameters — not for executing the function or displaying its results.
Defining an editor
A custom editor is a function that:
- Accepts a
DG.FuncCallobject as input - Returns a
DG.Widget - Is marked with
//meta.role: editorand an//output: widget <name>annotation
Note: While extending
DG.FuncCallEditoris optional, the returned widget must expose certain properties to support validation and input change tracking.
Required interface for the returned widget
| Property | Type | Description |
|---|---|---|
root | HTMLElement | Root element of the widget |
isValid | boolean | Indicates whether the inputs are valid |
onInputChanged | Observable<any> | Emits when user modifies inputs |
inputFor? | (name: string) => DG.InputBase<any> | Optional method to retrieve the input for a parameter name |
Sample editor
import * as grok from 'datagrok-api/grok';
import * as ui from 'datagrok-api/ui';
import { InputBase } from 'datagrok-api/ui';
// Optional: Extend DG.FuncCallEditor for convenience
class MyDummyEditor extends DG.FuncCallEditor {
boolCheck: InputBase<boolean>;
numInput: InputBase<number | null>;
constructor(call: DG.FuncCall) {
const root = ui.divV([]);
super(root);
this.boolCheck = ui.input.bool('Bool check', call.inputs['bool'] ?? false);
this.numInput = ui.input.int('Num', call.inputs['num'] ?? 0, {
onValueChanged: (value) => call.inputs['num'] = value,
});
this.boolCheck.onChanged.subscribe(() => call.inputs['bool'] = this.boolCheck.value);
root.append(this.boolCheck.root, this.numInput.root);
}
get onInputChanged(): rx.Observable<any> {
return rx.merge(this.boolCheck.onChanged, this.numInput.onChanged);
}
get isValid(): boolean {
return this.numInput.validate() && this.boolCheck.validate();
}
}
//name: dummyEditor
//meta.role: editor
//input: funccall call
//output: widget dialog
export function dummyEditor(call: DG.FuncCall): DG.Widget {
return new MyDummyEditor(call);
}
Usage example
//name: dummyScalar
//input: int num
//output: int res
//editor: DevTools:dummyEditor
export function dummyScalar(num: number): number {
return num * 102;
}
This tells the platform to render dummyEditor from the DevTools package as the editor for this function.
🚫 What the editor should NOT do
- Do not execute the function
- Do not show a Run button
- Do not handle result display or side effects
The purpose of the editor is solely to edit function parameters.
Annotating output dataframes with tags
Datagrok functions can annotate output dataframes with tags using the meta section of the output parameter annotation. This allows function authors to attach semantic information to the resulting table and its columns, such as database provenance, molecule handling hints, or custom metadata.
Note: This mechanism applies only to output parameters of type
dataframe.
Annotations are defined directly in the function signature using the meta section of the output parameter:
//output: dataframe {meta: {...}}
The meta object can contain both dataframe-level and column-level tags:
-
Dataframe-level tags
Any entry in themetaobject whose key does not match a column name, and whose value is not a JSON object, is treated as metadata for the dataframe itself. These key–value pairs are written directly to the dataframe metadata (table tags).Example:
//output: dataframe {meta: {".data-connection": "System:Datagrok"}}
This sets a dataframe-level tag:
-
.data-connection = "System:Datagrok" -
Column-level tags
If a key in themetaobject matches a column name and its value is a JSON object, that object is interpreted as metadata for the corresponding column. All nested key–value pairs are applied as column tags.Example:
//output: dataframe {meta: {"mol": {"DbTable": "structures", "DbSchema": "public", "DbColumn": "mol"}}}
This applies the following tags to the mol column:
DbTable = "structures"DbSchema = "public"DbColumn = "mol"
Dataframe-level and column-level metadata can be combined within a single meta block:
//output: dataframe {meta: {".data-connection": "System:Datagrok", "mol": {"DbTable": "structures", "DbSchema": "public", "DbColumn": "mol"}}}
Examples
TypeScript function
//name: Len
//description: Calculates the length of a string
//input: string s
//output: int n
export function getLength(s: string): number {
return s.length;
}
Python script
#name: Template
#description: Calculates number of cells in the table
#language: python
#sample: cars.csv
#input: dataframe table [Data table]
#output: int count [Number of cells in table]
count = table.shape[0] * table.shape[1]
Query
--name: protein classification
--connection: chembl
select * from protein_classification;
--end
Complex annotation example
#input: dataframe t1 {columns:numerical} [first input data table]
#input: dataframe t2 {columns:numerical} [second input data table]
#input: column x {type:numerical; table:t1} [x axis column name]
#input: column y {type:numerical} [y axis column name]
#input: column date {type:datetime; format:mm/dd/yyyy} [date column name]
#input: column_list numdata {type:numerical; table:t1} [numerical columns names]
#input: int numcomp = 2 {range:2-7} [number of components]
#input: bool center = true [number of components]
#input: string type = high {choices: ["high", "low"]} [type of filter]
#output: dataframe result {action:join(t1)} [pca components]
#output: graphics scatter [scatter plot]
See also: