Natural language processing
The Datagrok platform has a plugin designed for natural language processing. This plugin lets you work comfortably with files that have text content. To try it out, import your text files according to the instructions or use the provided demo files. The rest of the article is dedicated to the main applications of this domain integrated into the platform.
Text extraction
It all starts with extracting text. This is a building block for other, more
complex tasks. Due to the high demand, it is essential to support as many
popular text file formats as possible. The platform comes with a built-in
file browser for easy file management.
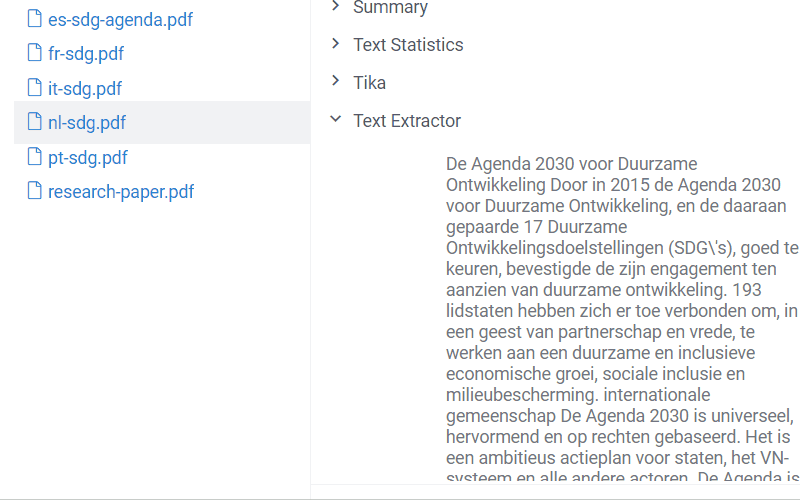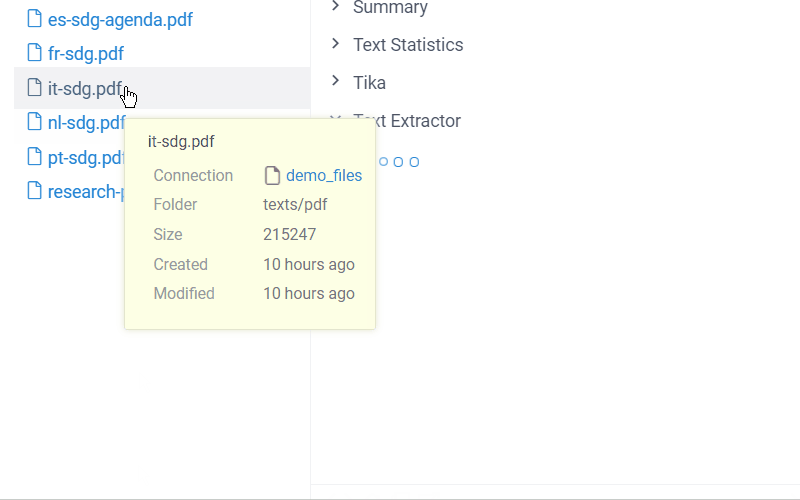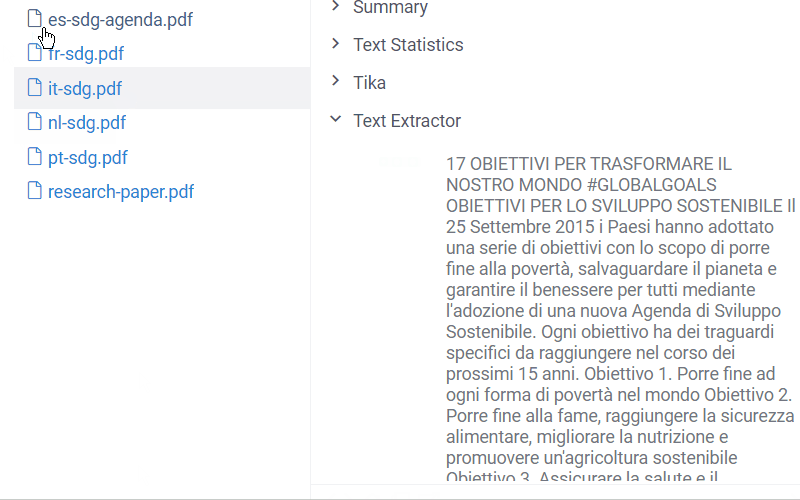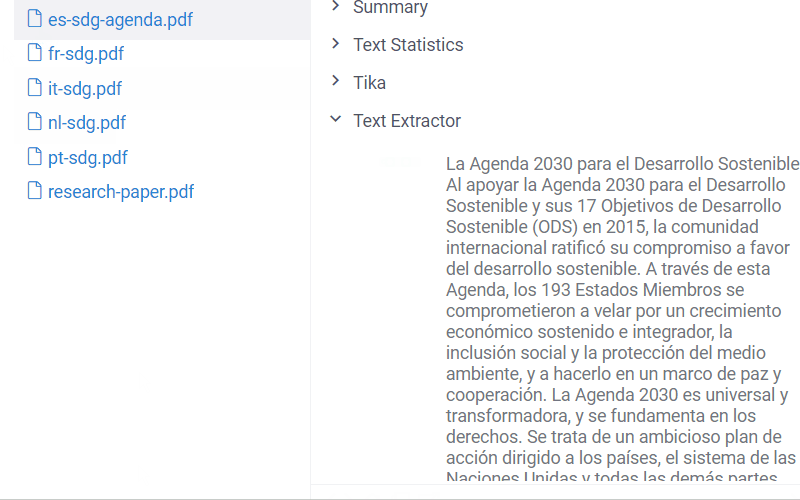
The NLP package extends it by processing text from pdf, doc, docx, odt, and other text formats.
 In addition to the file preview, the plugin enables the 'Text Extractor' info panel
In addition to the file preview, the plugin enables the 'Text Extractor' info panel
Language identification
Determining the language of a document is an important preprocessing step for many language-related tasks. Automatic language detection may be part of applications that perform machine translation or semantic analysis. Datagrok's language identification is powered by Google's Compact Language Detector v3 (CLD3) and supports over 100 languages. As with text extraction, this functionality is used in the Translation info panel.
Neural machine translation
The package creates a new info panel for text files. It uses AWS Translate service, which supports over 70 languages.
To translate a text, navigate to the file browser and select one of the demo files. Alternatively, open your personal folder and drag-and-drop your file to the platform. Now, whenever you click on the file, you will see a suggestion to translate it in the context panel on the right.
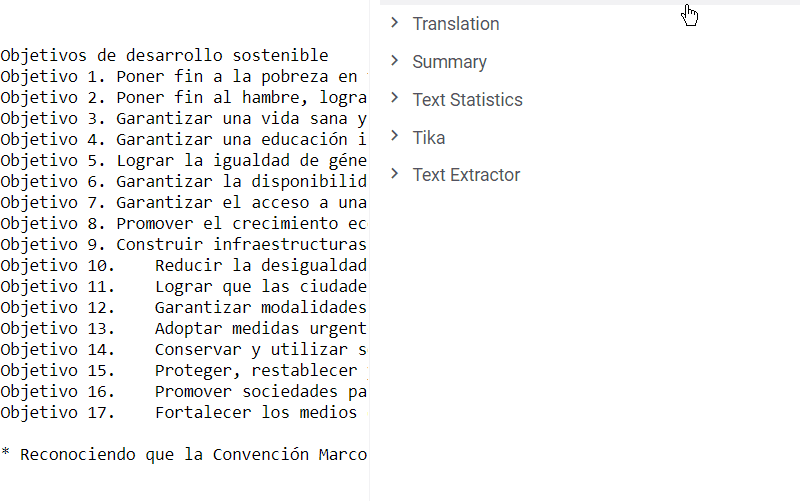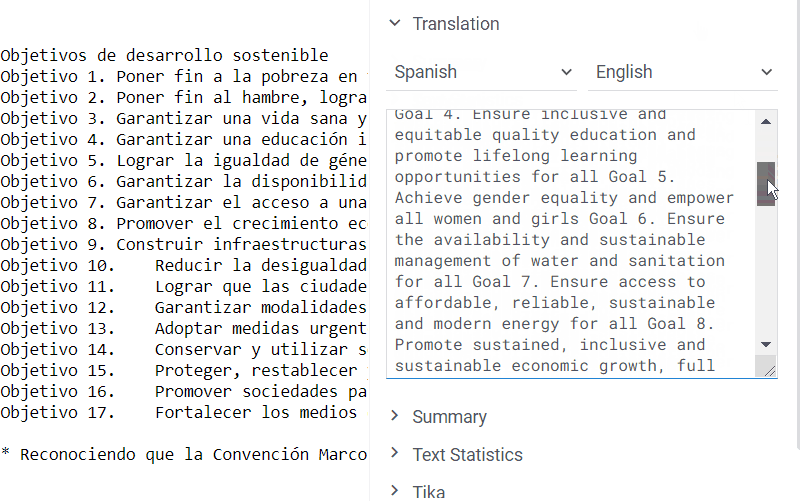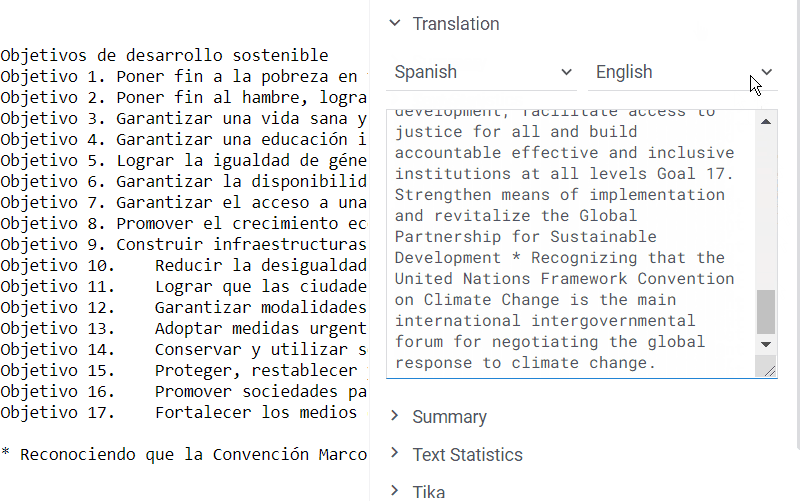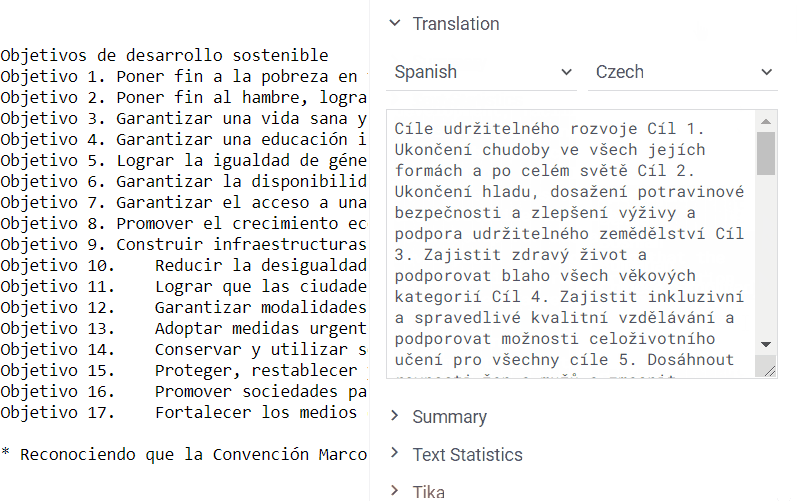
The language is identified automatically, but you always have a chance to change it manually. The default target language is English, so be sure to choose another option if the original text is in English.
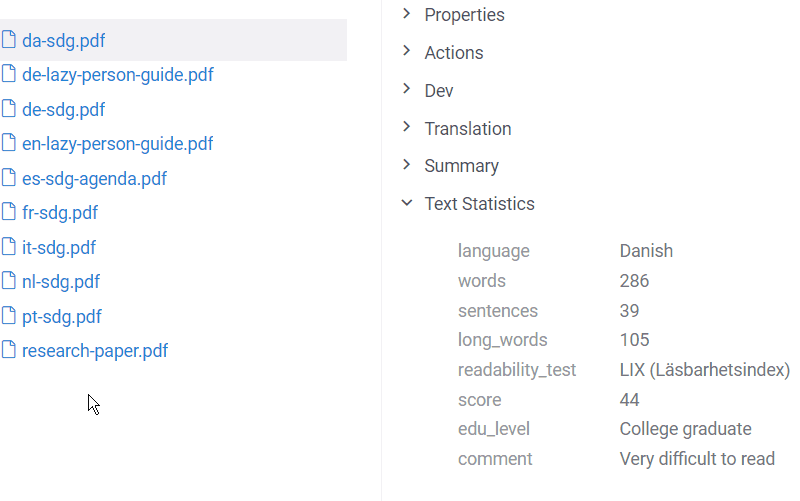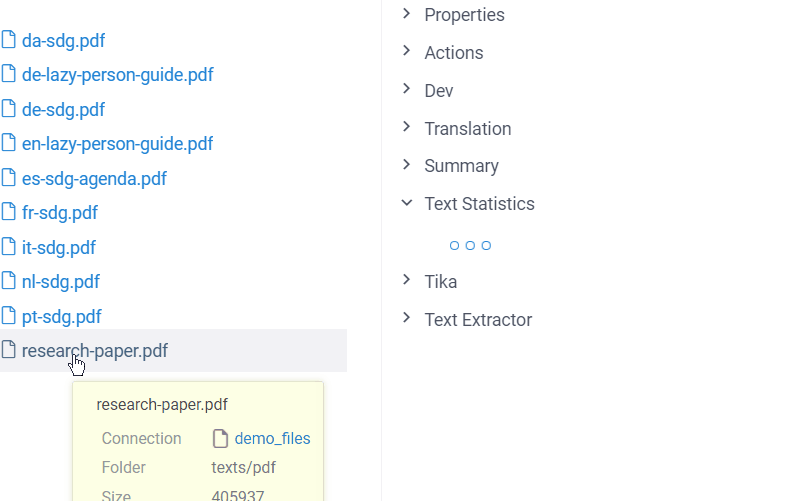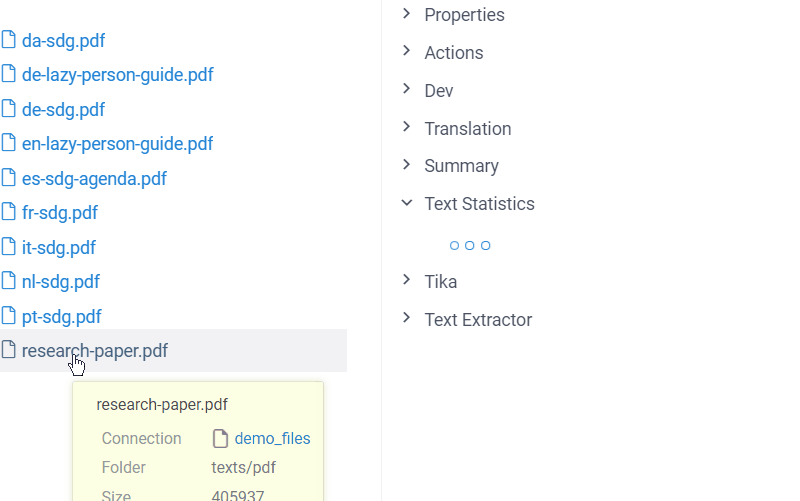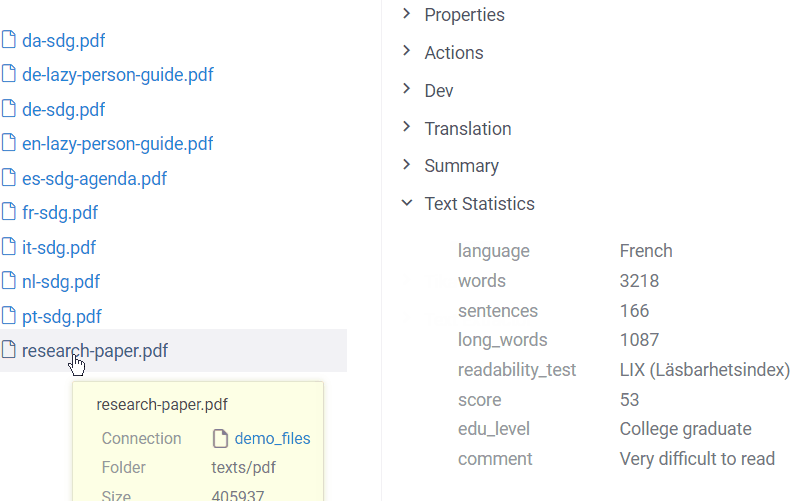
Text statistics
Increasingly often texts are analyzed for readability. Readability scores take into account various parameters: the average number of words per sentence or syllables per word, percentage of long words, etc.
The Text Statistics info panel calculates two common formulas:
- Flesch reading-ease test for English
- LIX formula for other languages
Videos
User Meeting 9: Natural Language Processing
See also: