Bioinformatics
Requirements
To access the bioinformatics functionality, install these packages using the Package Manager (on the Sidebar, click Manage > Packages):
- Required. Bio.
- Optional. Biostructure Viewer: Visualization of macromolecules in 3D.
- Optional. Helm: Rendering, editing, managing monomer libraries.
- Optional. Sequence Translator: Translates oligonucleotide sequences between multiple representations.
- Optional. Peptides: SAR analysis for sequences.
Datagrok lets you work with macromolecules both on the macro (sequence) level and atomic level:
- Data visualization and exploration
- Formats: such as FASTA (DNA/RNA/protein), delimiter-separated FASTA, HELM, BILN, PDB, and others. Handles nucleotides, natural and non-natural peptides, 3D-structures, and other modalities.
- Format conversion: SMILES to HELM, HELM to SMILES, Polytool notation, etc
- Automatic detection of sequences upon data import.
- Flexible and fast spreadsheet that shows both macro and small molecules.
- Interactive visualization of biological data.
- Customizable info panes with information about macromolecules and context actions.
- Sequence editing, search, and filtering.
- Sequence analysis
- Structure-Activity Relation (SAR) analysis
- Activity cliffs
- A fit-for-purpose application for SAR analysis for peptides
- A comprehensive ML toolkit for clustering, dimensionality reduction techniques, imputation, PCA/PLS, and other tasks. Built-in statistics.
- Flexible reporting and sharing options, including dynamic dashboards.
- Oligonucleotides chemical modifications and format conversion.
- Connection to chemistry level: split to monomers, and get the atomic-level structure.
- Extensible environment
- Ability to add or customize any functionality using scripts in Python, R, Matlab, and other supported languages.
- Ability to create custom plugins and fit-for-purpose applications.
- Enterprise-grade platform for efficient data access and management.
Data access
Datagrok provides a single, unified access point for organizations. You can connect to local file storage, clouds (Amazon S3, Google cloud, etc), SQL and NoSQL databases or any other of the 30+ supported data sources, retrieve data, and securely share data with others. Datagrok can ingest data in multiple file formats (such as Fasta or CSV) and multiple notations for nucleotide and amino acid / protein sequences, with natural and modified monomers, aligned and non-aligned forms.
You can also create macromolecule queries against data sources using built-in querying tools. To learn more about querying data and data access in general, see the Access section of our documentation.
Exploring biological data
Datagrok provides a range of tools for analyzing macromolecules (Top Menu > Bio). In addition, Datagrok provides a comprehensive machine learning toolkit for clustering, dimensionality reduction techniques, imputation, PCA/PLS, and other tasks (Top Menu > ML). Some of these tools can be applied directly to macromolecules.
When you open a dataset, Datagrok automatically detects macromolecules and makes macromolecule-specific context actions available. For example, when you open a CSV file containing sequences in FASTA format, the following happens:
- Data is parsed, and the semantic type macromolecule is assigned to the corresponding column.
- Macromolecules are automatically rendered in the spreadsheet.
- Hovering over monomers in the sequence shows their name and molecular structure, as per the active monomer library.
- Column tooltip now shows the sequence composition.
- Default column filter is now a subsequence search.
- A top menu item labeled Bio becomes available.
- Column and cell properties now show macromolecule-specific actions, such as sequence renderer and libraries options, sequence and macromolecule space preview, molecular structure and others.
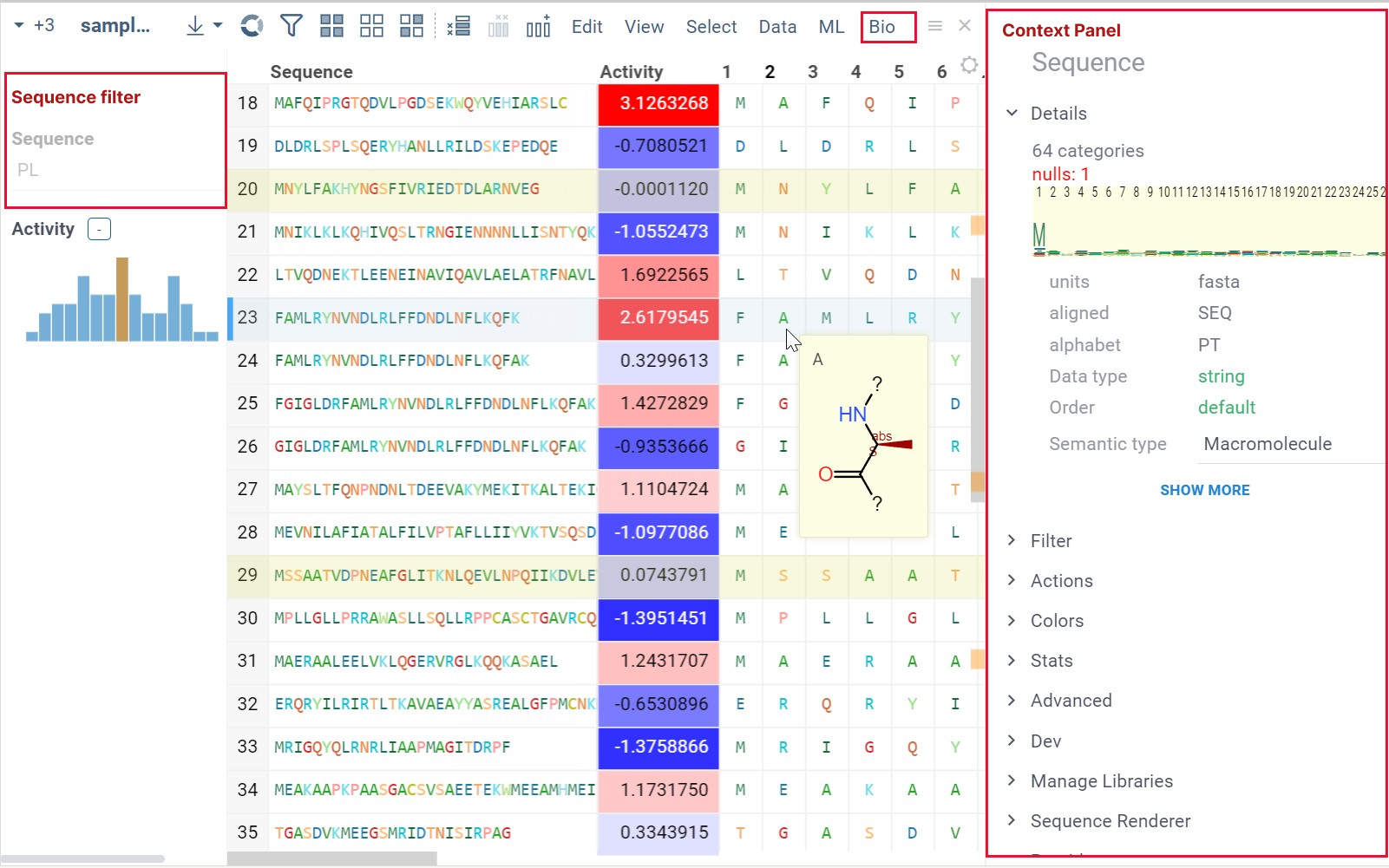
When you click on a column with macromolecules, you see the following in the Context Panel:
- Filter
- Manage Libraries
- Sequence Renderer: Rendering options.
- Peptides: From this pane, you can launch the SAR analysis for peptides.
Info pane options
Some info panes can be customized. To reveal an info pane's available options, hover over it:
- View and/or edit the underlying script (click the Script icon).
- Change parameters (click the Parameter icon).
- Change the info pane's settings (click the Gear icon).
- Append info pane as a column (click the More actions icon and select Add as a column).
To learn how to customize and extend the platform programmatically, see the Develop section of our documentation.
Info panes be extended with functions in any supported language.
Spreadsheet
The grid viewer lets you visualize and edit sequences and macromolecules. You can add new columns with calculated values, interactively filter and search rows, color-code columns, pin rows or columns, set edit permissions, and more.
Clicking on any sequence cell highlights the differing monomers in other sequences, allowing you to quickly identify similarities and differences.
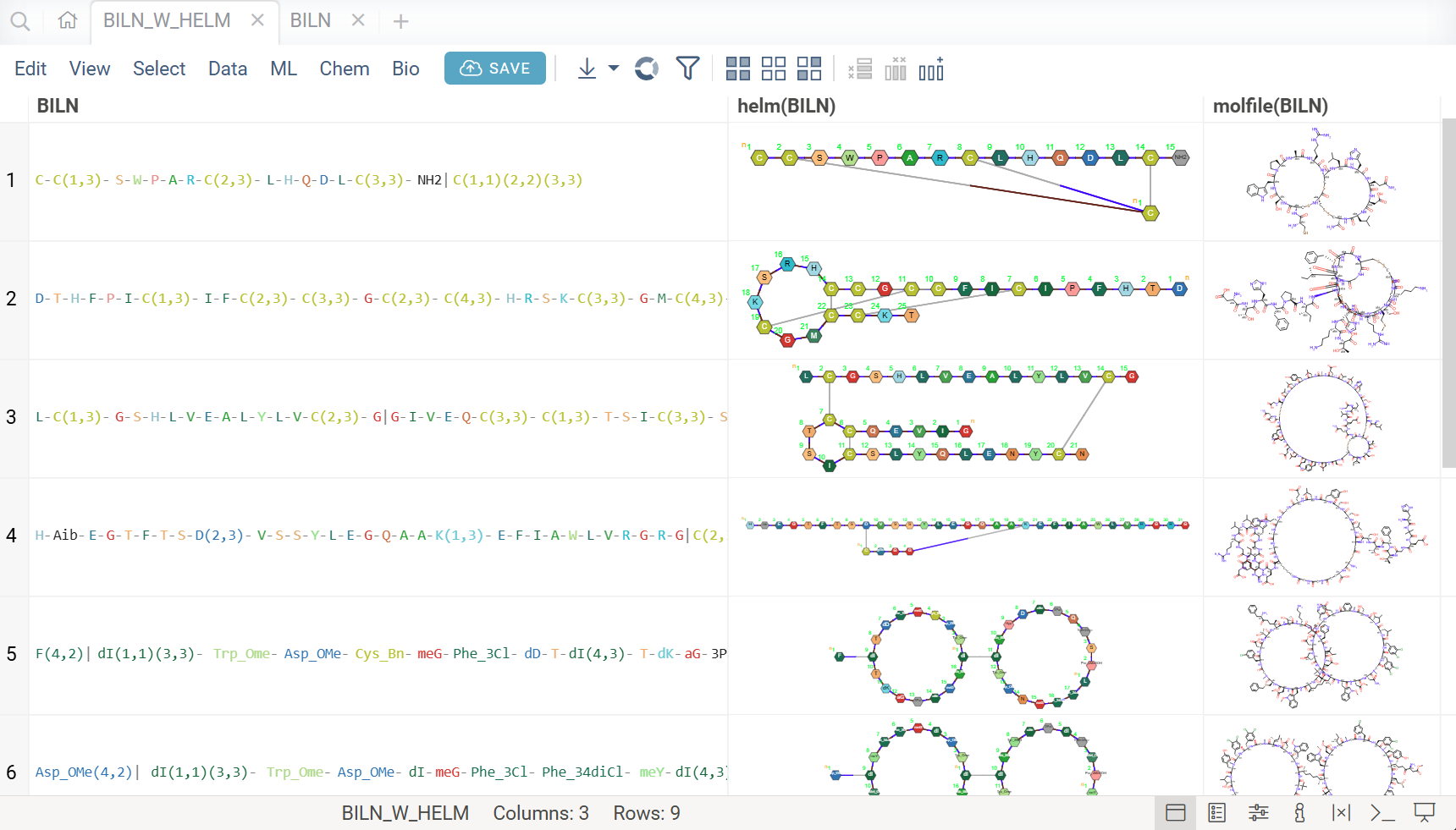
- FASTA
- HELM
- BILN
- PDB
Sequences in various modalities are color-coded based on monomer properties, natural analog or explicitely set colors.
HELM is used for macromolecules with non-natural monomers, circular and branching structures. The structures are displayed with colors corresponding to each monomer.
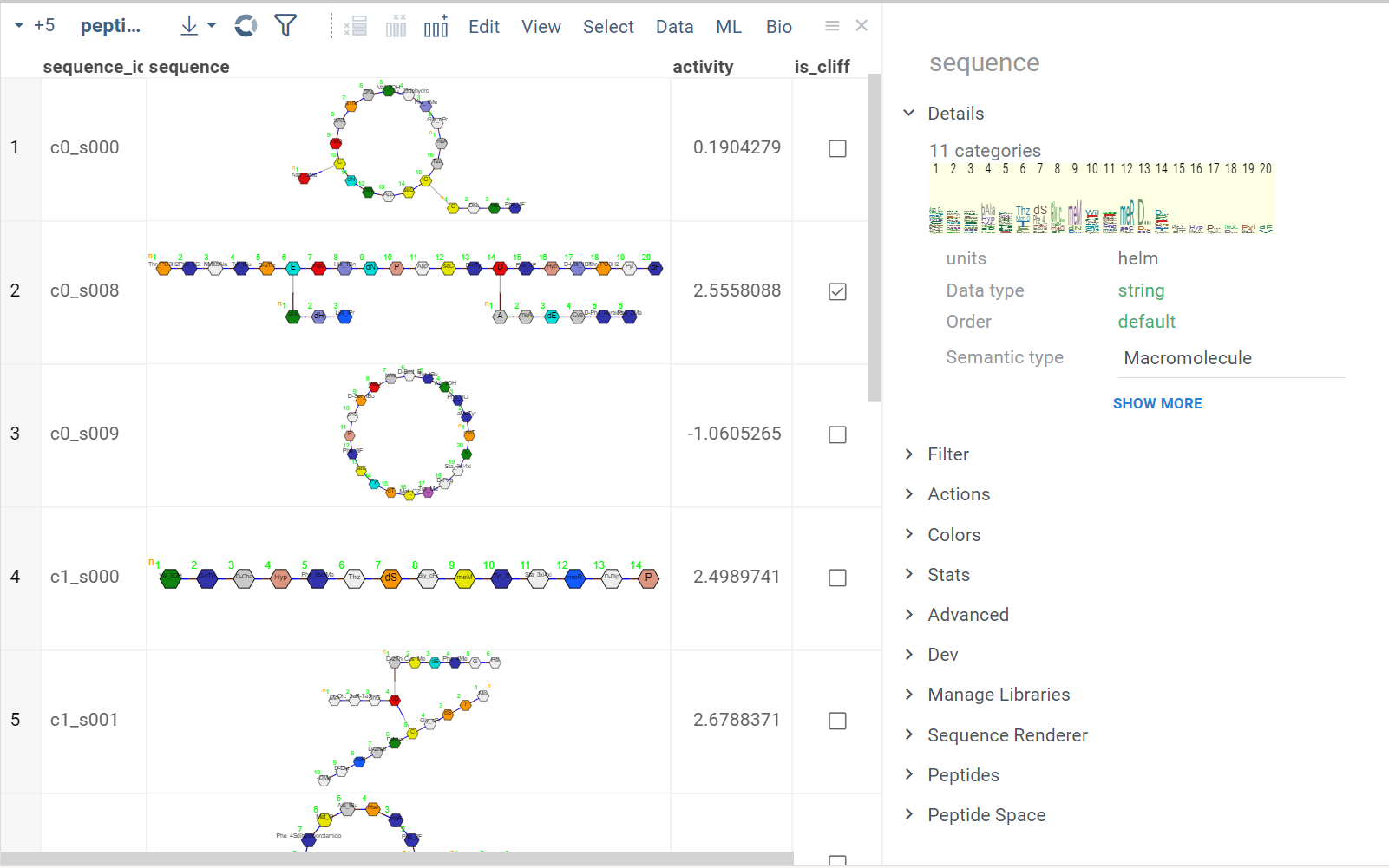
Various sseparated formats, such as BILN, '.', '-' or '/' separators are supported. Such sequences can encode non-canonical monomers (see Monome Manager), multiple chains, branching and cyclic structures.
For PDB files, cells display a preview of the 3D structure. When you click a cell, a separate viewer opens up, allowing you to rotate, zoom in, or switch the color scheme.

Interactive sequence header
Long biological sequences, such as antibodies, are displayed with an interactive, scrollable WebLogo and conservation headers. You can click on any position in the sequence to highlight it and open a position statistics viewer, which shows the distribution of activities across different monomers at that site
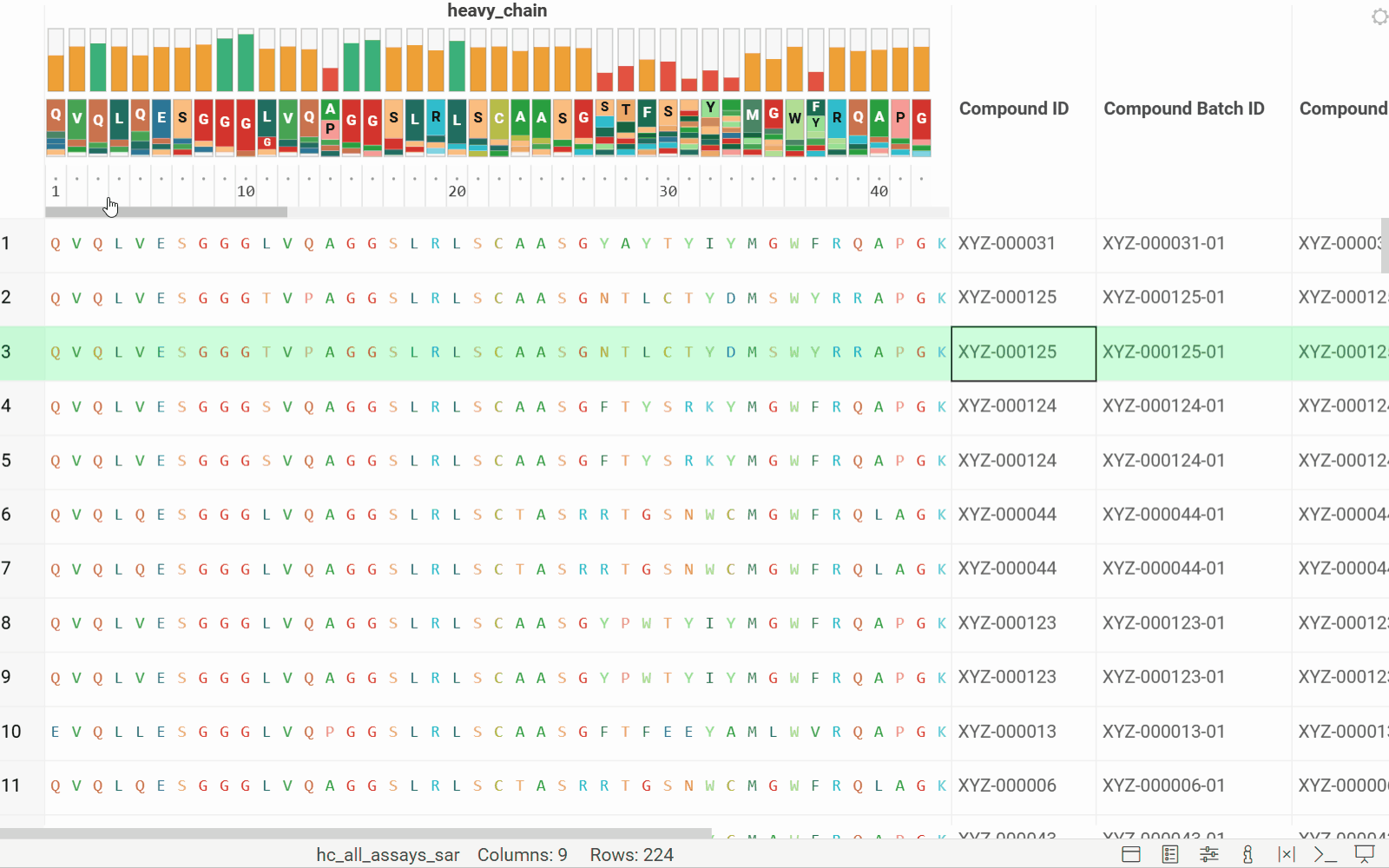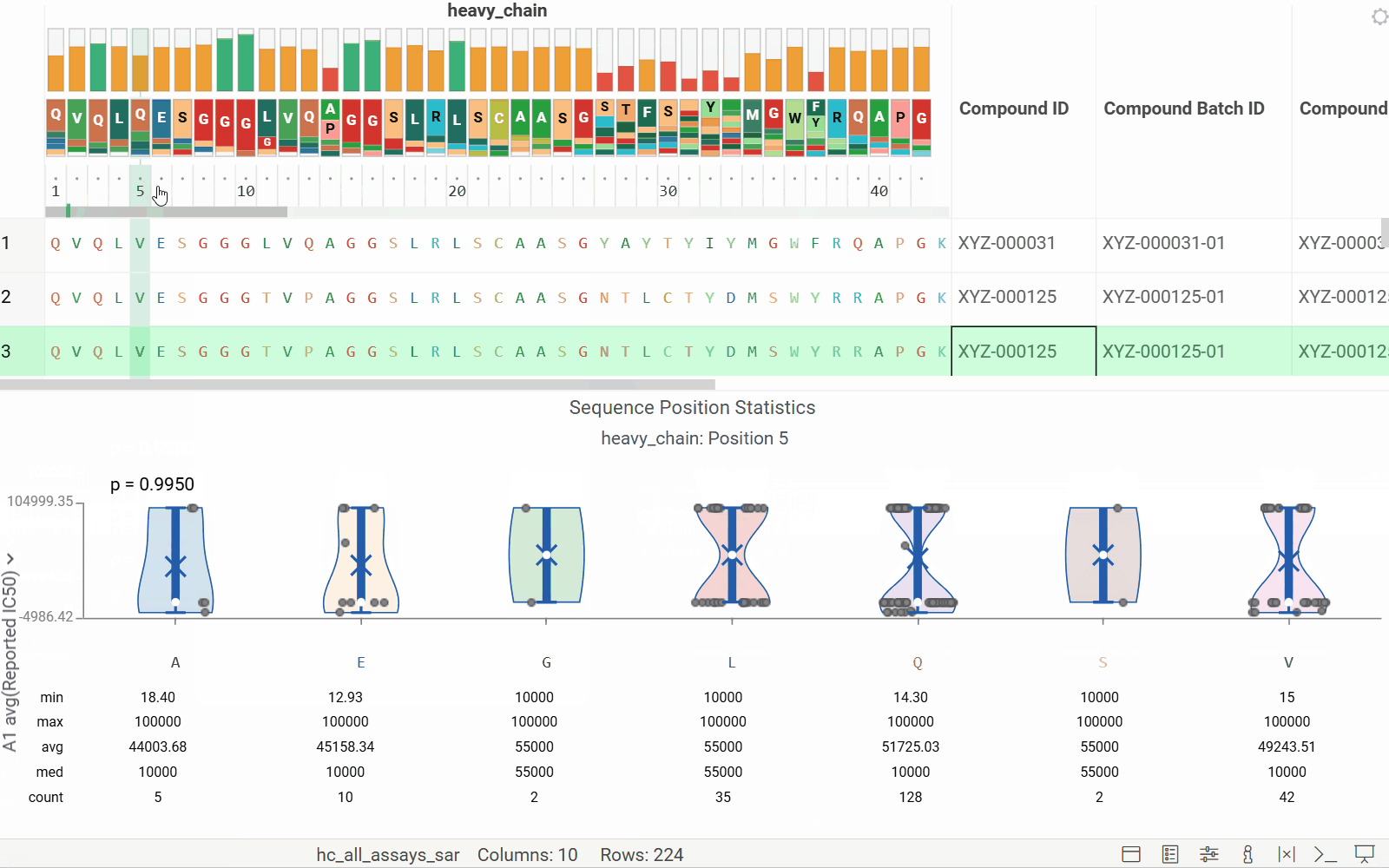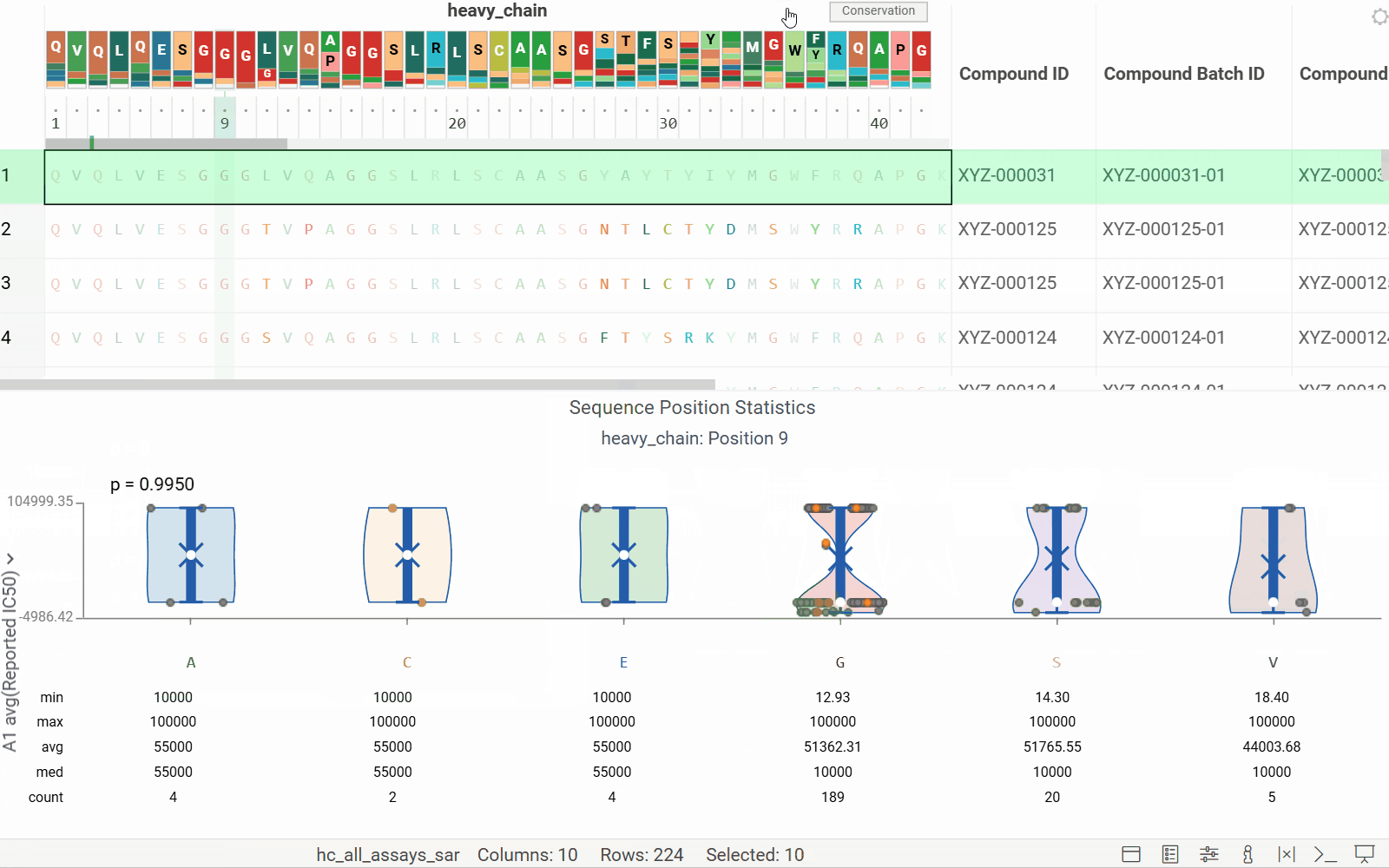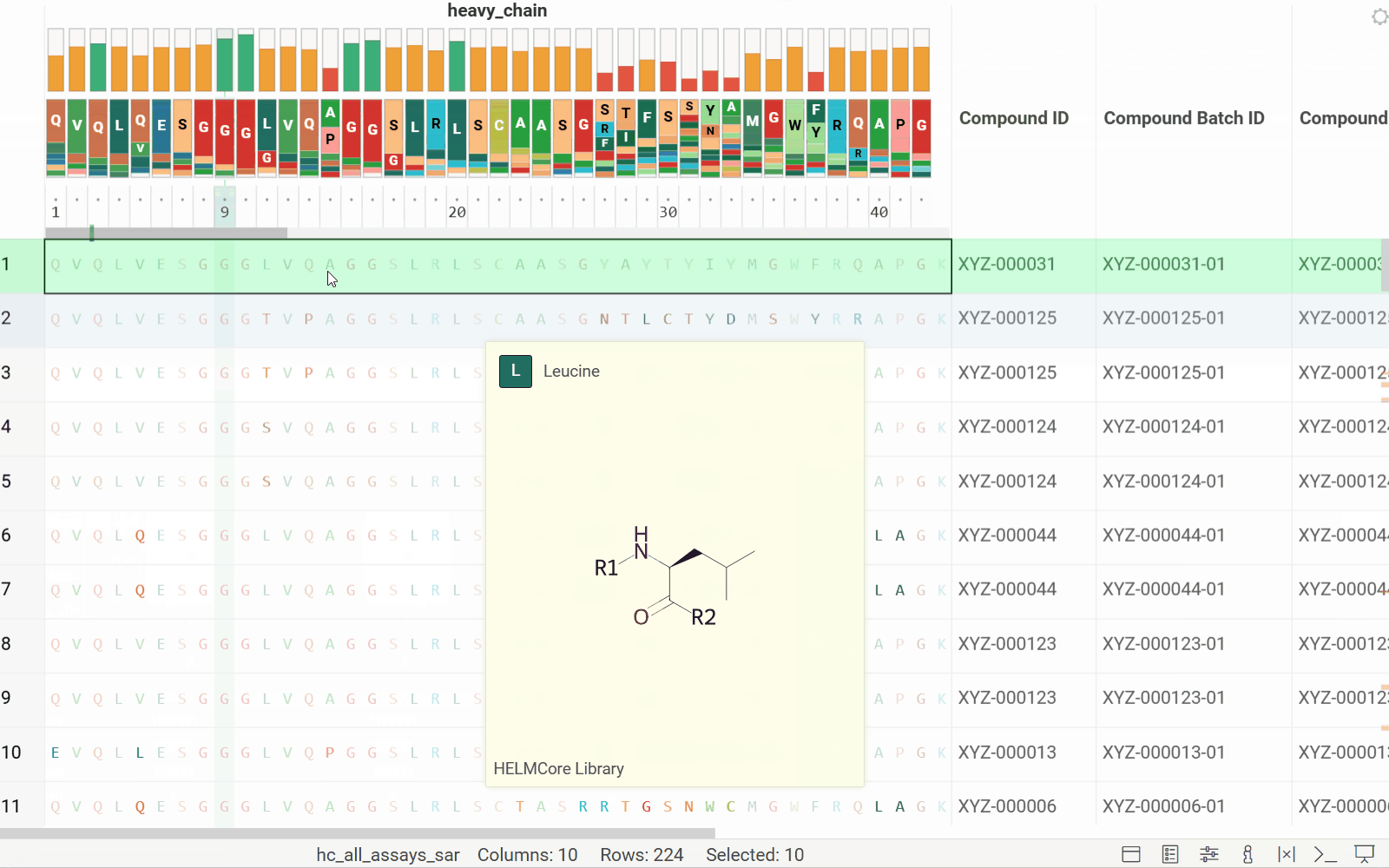
Macromolecule aware viewers
Datagrok viewers recognize and display macromolecules. The majority of the viewers were built from scratch to take advantage of Datagrok's in-memory database, enabling seamless access to the same data across all viewers. Viewers also share a consistent design and usage patterns. Any action taken on one viewer, such as hovering, selecting, or filtering, is automatically applied to all other viewers, creating an interconnected system ideal for exploratory data analysis.
Macromolecule-specific viewers include sequence logo, 3D structure viewers (biostructure and NGL viewer), and sequence tree viewers. Examples of general-purpose viewers that can be used to analyze biological data include a scatterplot, a network diagram, a tile viewer, a bar chart, a form viewer, and trellis plot, and others.
Examples
- Spreadsheet
- Scatterplot
Composition analysis for MSA.

Activity cliffs analysis using a scatterplot.
All viewers can be saved as part of the layout or a dashboard. Some viewers offer built-in statistics.
To learn how to use viewers to explore data, complete this tutorial or visit the Visualize section of our documentation.
You can add custom viewers.
Analyzing docking results
To explore the binding interactions between small ligand molecules and biological structures, you can use either the NGL or biostructure viewer. Both viewers visualize the docked ligands in their spatial context and let you examine their orientation and positioning within the binding site.
How to use
Prerequisites: Prepare the simulation data in two separate files:
- File 1: Contains the structure of a macromolecule in a supported format, such as PDB.
- File 2: Contains the simulation results of the position of small molecules relative to the structure.
To visualize docked ligands, follow these steps:
- Open the table with ligands (File 2) in Datagrok.
- Add either the NGL or biostructure viewer.
- In the viewer, drop the file with the macromolecule structure (File 1).
You can interact with the ligands as follows:
- To visualize docking for a particular ligand, click it. You can visualize multiple ligands simultaneously by selecting or hovering over rows.
- If one ligand is selected, it will be visualized with a full-color ball+stick representation.
- For multiple ligands:
- The current row ligand is shown in green.
- The mouse-over row ligand is shown in light gray.
- The selected row(s) ligands is shown in orange.
You can further analyze the ligand data by applying filters, allowing you to focus on specific subsets based on criteria such as binding energy estimates or scoring functions. You can also cluster the ligands based on one or more parameters to identify patterns and groups within the dataset.
Sketching and editing
You can create and edit macromolecules:
- For DNA, RNA, and protein sequences in the linear format, you can edit the sequences.
- For HELM notation, you can add or remove monomers and modify connections. The editor supports circular and branching structures.
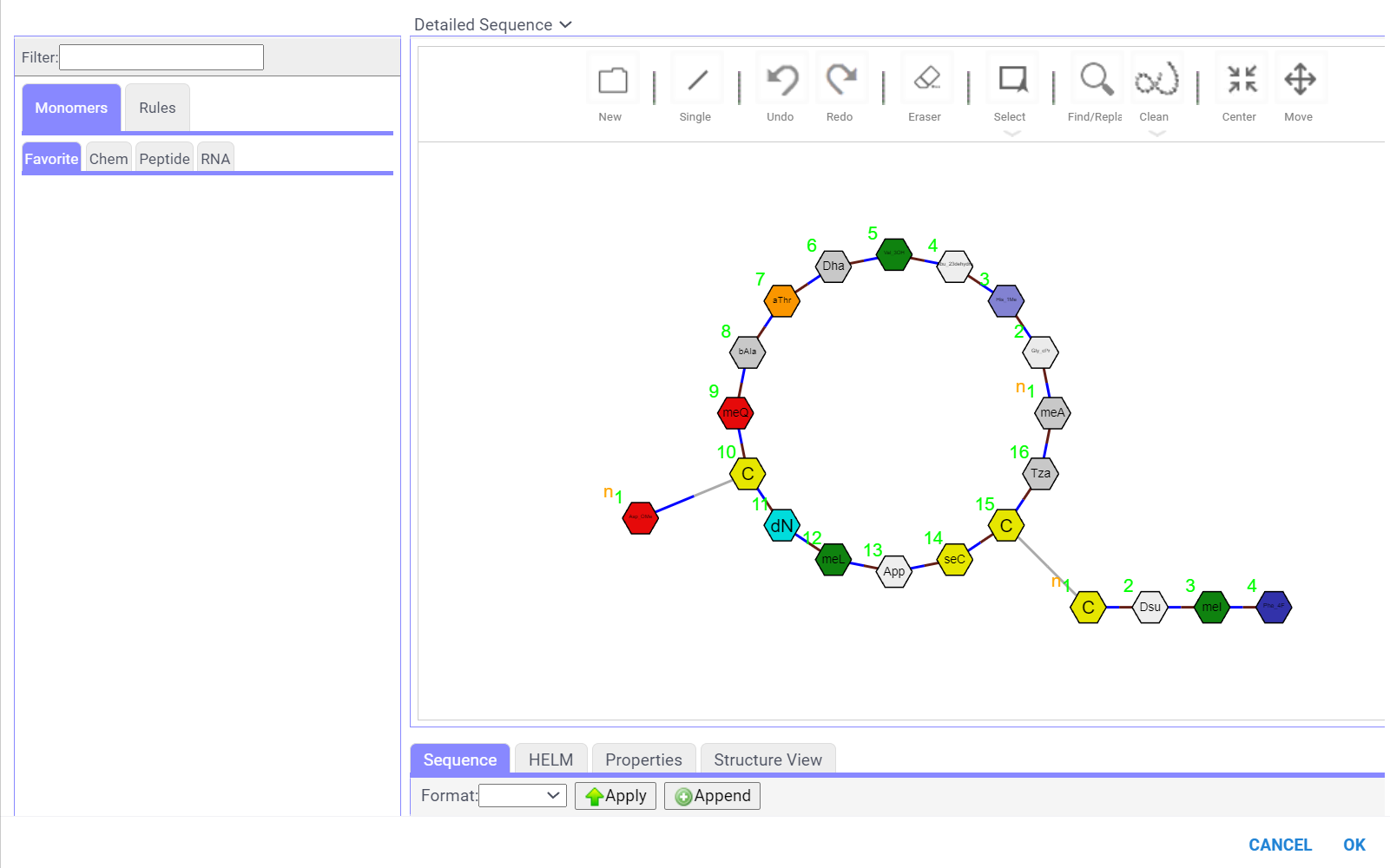
Searching and filtering
Datagrok offers an intuitive searching and filtering functionality for exploring datasets.
Filtering
For sequence-based filtering, Datagrok uses an integrated HELM editor for HELM notations and text-based filter for linear notations. All filters are interactive — hovering over categories or distributions in the Filter Panel instantly highlights relevant data points across all viewers.
How to filter
To filter by sequence:
- On the Top Menu, click the Filter icon to open the Filter Panel. The panel shows filters for all dataset columns. By default, the subsequence filter is displayed on top but you can rearrange, add, or remove filter columns by using available controls.
- To enter a subsequence, click the Click to edit button.
- Once finished, click OK to apply the filter.
To clear the filter, use the checkbox provided. To remove the filter altogether, use the Close (x) icon.
Substructure Search
The substructure search feature finds sequences containing a specific pattern or motif and filters the dataset. Search results can be also presented as a new boolean column in the table, where checkboxes indicate matches. You can color-code results for visual profiling or use the column as an additional filter for further analysis.
How to use
- In the Top Menu, select Bio > Search > Substructure Search.... Filter panel will open with Sequence column filter.
- Enter or paste the sequence pattern in the provided substructure field. This will filter the dataset based on prompt.
Similarity Search
Similarity search identifies sequences most similar to a target sequence using configurable distance metrics (Needleman-Wunsch, Hamming, Levenshtein, or monomer chemical distance). This is useful for finding close homologs or variants of a known sequence.
The tool generates an interactive results grid showing similar sequences ranked by similarity score, with visual highlighting of differences between the target and matches. You can adjust the similarity cutoff and choose different distance metrics and fingerprint types for comparison.
How to use
- In the Top Menu, select Bio > Search > Similarity Search. A similarity search viewer is added to the view.
- Click on any sequence in the main grid to see top similar sequences to it.
- Configure parameters:
- Cutoff: Similarity threshold (0-1)
- Distance metric: Choose from Needleman-Wunsch, Hamming, Levenshtein, or monomer chemical distance
- Fingerprint type: For monomer chemical distance (Morgan, RDKit, etc.)
- Number of neighbors: How many similar sequences to return
- Results appear in an interactive grid, sorted by similarity. Click any result to highlight differences on the context panel.
Diversity Search
Diversity search finds the most diverse subset of sequences in your dataset, useful for selecting representative samples or reducing redundancy while maintaining coverage of sequence space. The algorithm uses distance-based metrics to identify sequences that are maximally different from each other.
How to use
- In the Top Menu, select Bio > Search > Diversity Search. A diversity search viewer is added to the view.
- Configure parameters:
- Number of diverse sequences: How many sequences to select
- Distance metric: Choose the metric for calculating diversity
- Fingerprint type: For chemical distance calculations
- Results appear in a new table containing the most diverse sequences from your dataset.
To learn more about filtering, watch this video or read this article.
Manage monomer libraries
Datagrok enables you to manage monomer libraries for various macromolecule types, including DNA, RNA, peptides, and custom structures. These libraries define the building blocks, or monomers, that compose polymers and store detailed metadata about each monomer, such as properties, labels, and molecular structures. This metadata supports flexible and accurate functionality across the platform, such as the To Atomic Level conversion, sequence analysis, and polymer enumeration in tools like Polytool. By managing monomer libraries, users can select specific monomers for custom analyses and workflows, ensuring precise control over macromolecule representation and manipulation.
The default HELM monomer library is pre-installed with the Bio package. You can add your own monomer libraries using the view accessible from Top Menu > Bio > Manage > Monomer Libraries:

To make the monomers from a library available throughout Datagrok, select the checkbox next to the library name. Similarly, to exclude monomer library, uncheck the checkbox. The changes are applied immediately and reflected throughout the platform.
To add a new monomer library file, click ADD button. All monomer library files are validated against the standard HELM JSON schema and must fully conform to it. The added files will be stored under AppData/Bio/monomer-libraries in file shares.
You can also merge selected monomer libraries into a single file by clicking MERGE button. The merged file will be saved in the same location as the original files or can be downloaded. Not needed monomer libraries can be removed by clicking Delete icon next to their name.
Some combinations of monomer libraries can contain conflicting monomer definitions (different structures/properties for same monomer symbol). In such cases, you will see duplicate monomer symbols, along with their structures and sources on the right side of the view. You can manually resolve these conflicts by selecting the correct monomer structure for the given symbol, and the choice will be immediately applied throughout the platform.

Manage monomers
Apart from being able to manage which monomer libraries are used, you can also manage and edit individual monomers within them. To do so, click on the Edit icon next to the monomer library name. You can also access monomer management through Top Menu > Bio > Manage > Monomers. Monomer manager allows you to view, add, edit and delete monomers within the selected library.
The Monomer manager view consists of two main parts: On the left side, you can see a molecular sketcher, where you can draw the structure of the monomer, along with the monomer properties editors such as name, symbol, natural analog, r-groups, colors and others. On the right side, you can see a list of all monomers in the library, along with their structures and properties. You can select a monomer from the list to view or edit its properties, or delete it from the library.

How to use
- To remove a monomer from the library, right click on the monomer in the table, and select Remove Monomer. Alternatively, you can select the monomer and click the Delete icon on the top ribbon pannel. You can also remove multiple monomers at once by selecting them and clicking the Delete icon.

- To add a new monomer to the library, click the Add icon on the top ribbon panel. This will create a blank monomer, for which you can draw molecular structure, fill in the properties and save it to the library.
- If the given symbol or molecular structure already exists in the library, you will be prompted about it.
- The molecular structure is requeired to have at least one R-group.
- Upon drawing the structure, monomer natural analogue will be automatically set to the most similar natural monomer (based on tanimoto similarity of corresponding Morgan fingerprints).

- You can also edit existing monomers, or use them as template for new ones. To do so, simply click on any monomer in the table, and its properties will be loaded into the editor. You can then modify the properties, and save the changes to the library. To find a monomer in the table, you can use standard datagrok filters, which enables you to search based on names, symbols, molecular substructure, similarity, and other properties.

Sequence analysis
Sequence composition
You can create a sequence logo to show the letter composition for each position in a collection of sequences. A sequence logo is usually created from a set of aligned sequences and helps identify patterns and variations within those sequences. A common use is to visualize protein-binding sites in DNA or functional motives in proteins.

How to use
- In the Top Menu, select Bio > Composition Analysis. The sequence logo viewer is added to the Table View.
- To edit parameters, hover over the viewer's top and click the Gear icon.
Sequence space
Sequence space visualizes a collection of sequences in 2D such that similar sequences are placed close to each other (geekspeak: dimensionality reduction, tSNE, UMAP, distance functions). This allows to identify clusters of similar sequences, outliers, or patterns that might be difficult to detect otherwise. Results are visualized on the interactive scatterplot.
Sequence space analysis is particularly useful for separating groups of sequences with common motifs, such as different variants of complementarity-determining regions (CDRs) for antibodies.
How to use
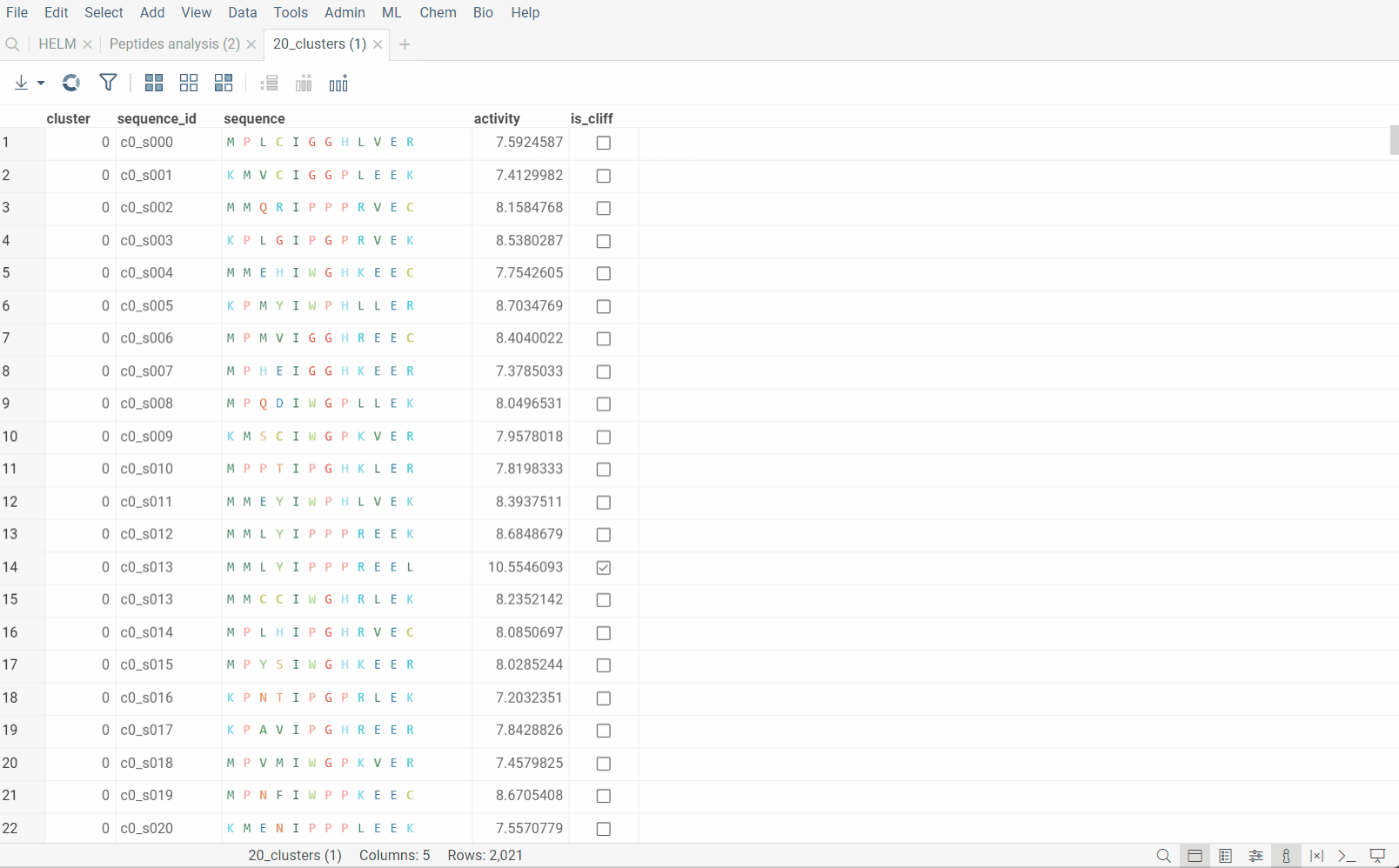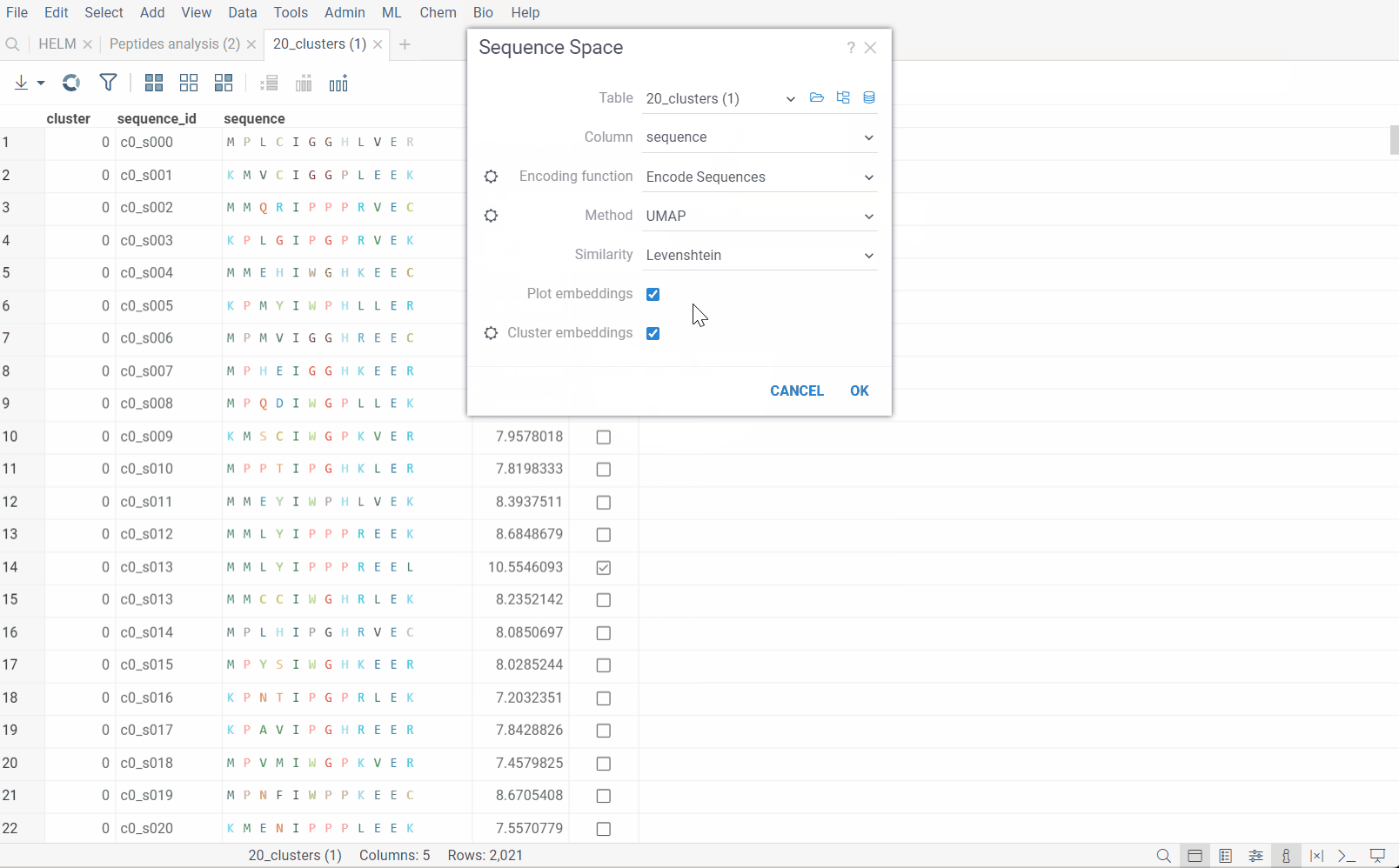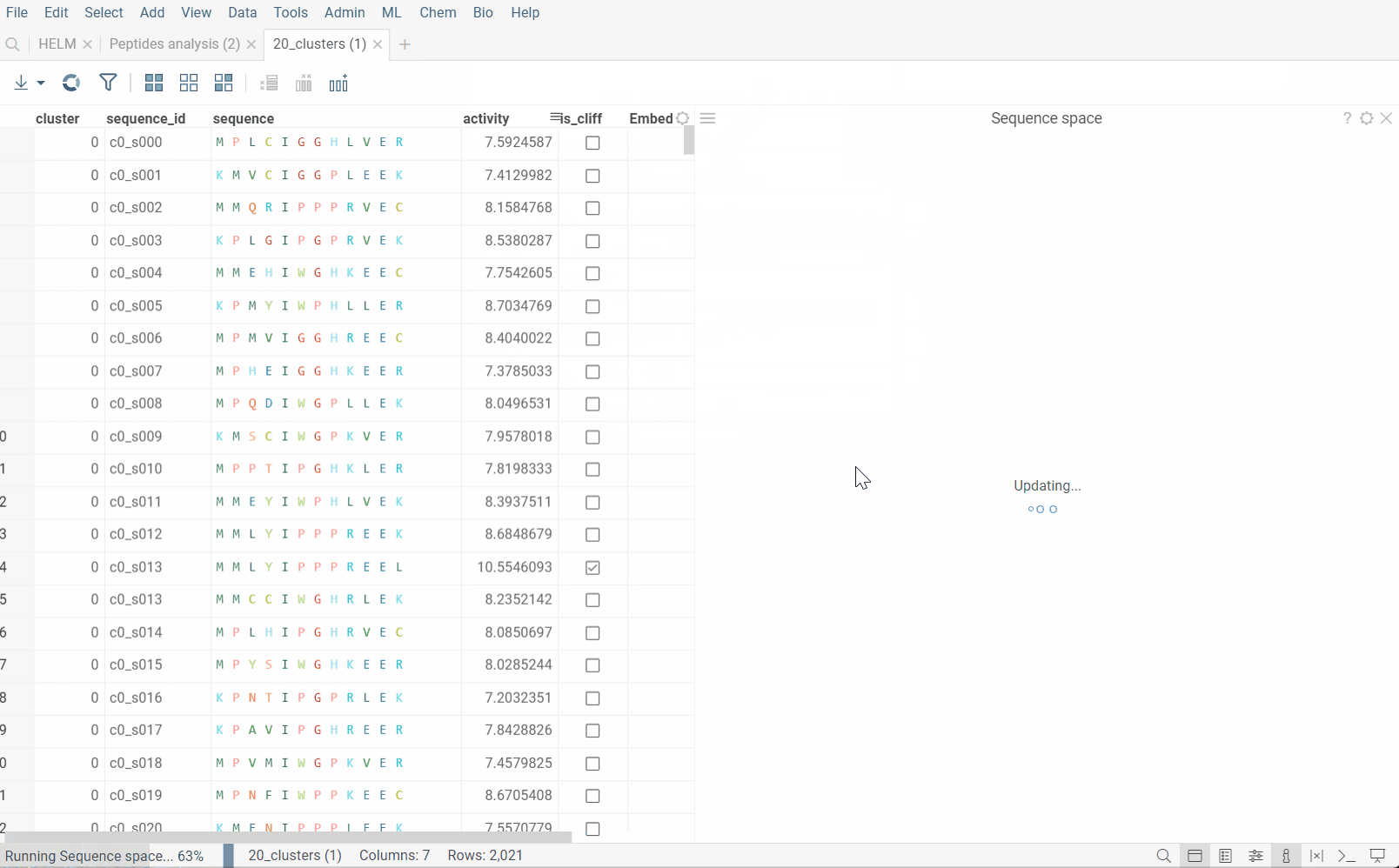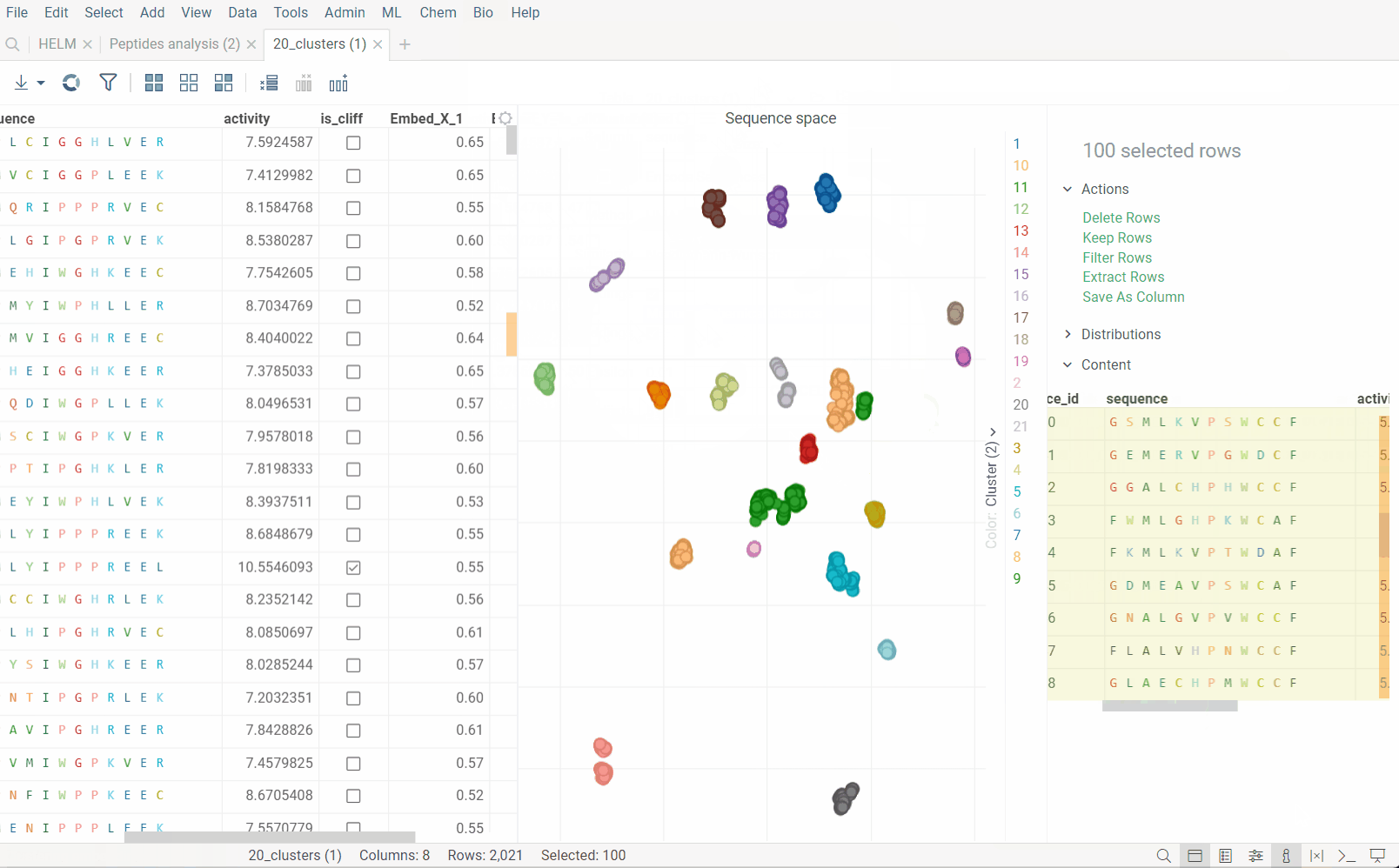
Go to the Top Menu and select Bio > Analyse > Sequence Space... This opens a Sequence Space parameter dialog.
The dialog has the following inputs:
-
Table: The table containing the column of sequences.
-
Column: The column containing the sequences.
-
Encoding function: The encoding function that will be used for pre-processing of sequences. For non-helm notation sequences, only one encoding function is available, that will encode them in single character form and calculate the substitution matrix for each individual monomer. For Helm sequences, apart from prior function, another one is offered that will use chemical fingerprint distances between each macromolecule to calculate distance matrix. The
Encode sequencesfunction has 3 parameters which you can adjust using the gear (⚙️) button next to the encoding function selection:- Gap open penalty: The penalty for opening a gap in the alignment (used for Needleman-Wunsch algorithm).
- Gap extend penalty: The penalty for extending a gap in the alignment (used for Needleman-Wunsch algorithm).
- Fingerprint type: The type of molecular fingerprints that will be used to generate monomer substitution matrix.
-
Method: The dimensionality reduction method that will be used. The options are:
- UMAP: UMAP is a dimensionality reduction technique that can be used for visualization similarly to t-SNE, but also for general non-linear dimension reduction.
- t-SNE: t-SNE is a machine learning algorithm for dimensionality reduction developed by Geoffrey Hinton and Laurens van der Maaten. It is a nonlinear dimensionality reduction technique that is particularly well-suited for embedding high-dimensional data into a space of two or three dimensions, which can then be visualized in a scatter plot.
Other parameters for dimensionality reduction method can be accessed through the gear (⚙️) button next to the method selection.
-
Similarity: The similarity/distance function that will be used to calculate pairwise distances. The options are:
- Needleman-Wunsch: Needleman-Wunsch is a dynamic programming algorithm that performs a global alignment on two sequences. It is commonly used in bioinformatics to align protein or nucleotide sequences.
- Hamming: Hamming distance is a metric for comparing two macromolecules of same length. Hamming distance is the number of positions in which the two monomers are different.
- Monomer chemical distance: Similar to Hamming distance, but instead of penalizing the mismatch of monomers with -1, the penalty will be based on the chemical distance between the two monomers. The chemical distance is calculated using the chemical fingerprint of the monomers.
- Levenshtein: Levenshtein distance is a string metric for measuring the difference between two sequences. Informally, the Levenshtein distance between two sequences is the minimum number of single-monomer edits (insertions, deletions or substitutions) required to change one sequence into the other.
-
Plot embeddings: If checked, the plot of the embeddings will be shown after the calculation is finished.
-
Postprocessing: The postprocessing function that will be applied to the resulting embeddings. The options are:
- None: No postprocessing will be applied.
- DBSCAN: The DBSCAN algorithm groups together points that are closely packed together (points with many nearby neighbors), marking as outliers points that lie alone in low-density regions (whose nearest neighbors are too far away). The DBSCAN algorithm has two parameters that you can adjust through the gear (⚙️) button next to the postprocessing selection:
- Epsilon: The maximum distance between two points for them to be considered as in the same neighborhood.
- Minimum points: The number of samples (or total weight) in a neighborhood for a point to be considered as a core point. This includes the point itself.
- Radial Coloring: The radial coloring function will color the points based on their distance from the center of the plot. The color will be calculated as a gradient from the center to the border of the plot.
WebGPU Acceleration
WebGPU is an experimental feature that enables GPU-accelerated calculations directly in the browser. We have implemented WebGPU support for KNN graph generation (with support for all distance functions including Needleman-Wunsch, Levenshtein, etc.) and UMAP algorithm, which can provide up to 100x speedup for large datasets.
To enable WebGPU acceleration, check the corresponding option in the gear (⚙️) button next to the method selection (UMAP).
Requirements and limitations:
- Requires hardware GPU support
- To ensure your browser uses the high-performance GPU:
- Go to system settings → Display settings → Graphics settings
- Find your browser in the app list
- Set it to use "High performance" GPU
If WebGPU is not supported in your browser, the checkbox will not appear in the dialog.
Hierarchical clustering
Hierarchical clustering groups sequences into an interactive dendrogram. In a dendrogram, distance to the nearest common node represents the degree of similarity between each pair of sequences. Clusters and their sizes can be obtained by traversing the trunk or branches of the tree and deciding at which level to cut or separate the branches. This process lets you identify different clusters based on the desired level of similarity or dissimilarity between data points.
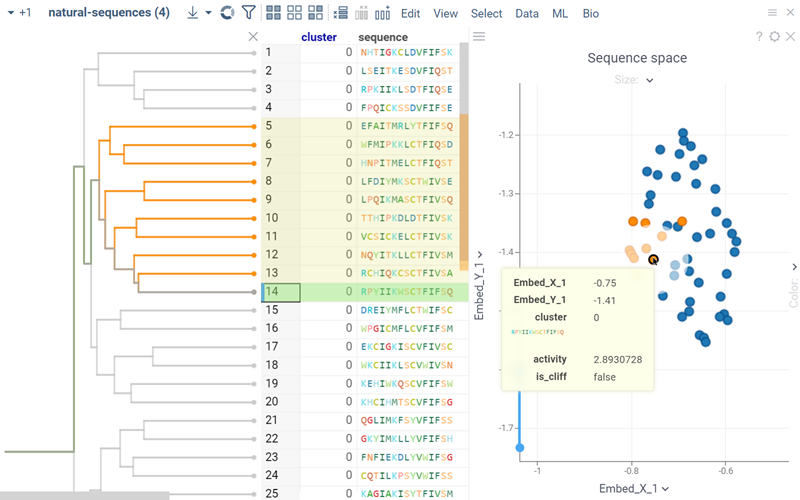
How to use
To add a dendrogram viewer, do the following:
- In the Top Menu, select Bio > Hierarchical clustering. A dialog opens.
- In the dialog, select the parameters and click OK to add the dendrogram to the Table View.
Multiple sequence alignment (MSA)
Multiple Sequence Alignment aligns sequences for macromolecules in any format (fasta, separator, HELM, biln, etc). Datagrok automatically picks an alignment mode based on the sequence column and exposes a choice of engines for non-canonical peptides.
For DNA, RNA, and natural peptides, Datagrok uses KAlign, which can be modified to work with custom substitution matrices.
For non-canonical sequences, the MSA dialog discovers all installed engines and lets you select one. The following engines are available out of the box:
- HELM MSA. An in-browser progressive aligner built from scratch for arbitrary HELM topologies. It aligns linear, cyclic (head-to-tail, lariat), stapled, CHEM-bridged macrocyclic, branched, and multi-chain sequences with any number of non-canonical monomers. Cyclic peptides are automatically rotated to a common frame before alignment, and connection positions are remapped after gap insertion so the output HELM remains valid. The engine uses UPGMA-guided progressive alignment for small sets and center-star alignment for large ones, with affine gap penalties and separate terminal-gap control. Because it runs entirely in the browser, no Docker container is required and thousands of sequences align in under a second.
- PepSeA. PepSeA aligns multiple linear peptide sequences in HELM notation of up to 256 non-natural amino acids. It runs in a Docker container and is best suited for linear peptides where a chemistry-aware substitution matrix is desirable.
Each engine exposes its own parameters (gap penalties, alignment method, and engine-specific options) directly in the MSA dialog.
How to use
To perform MSA, do the following:
-
In the Top Menu, select Bio > MSA.... A dialog opens.
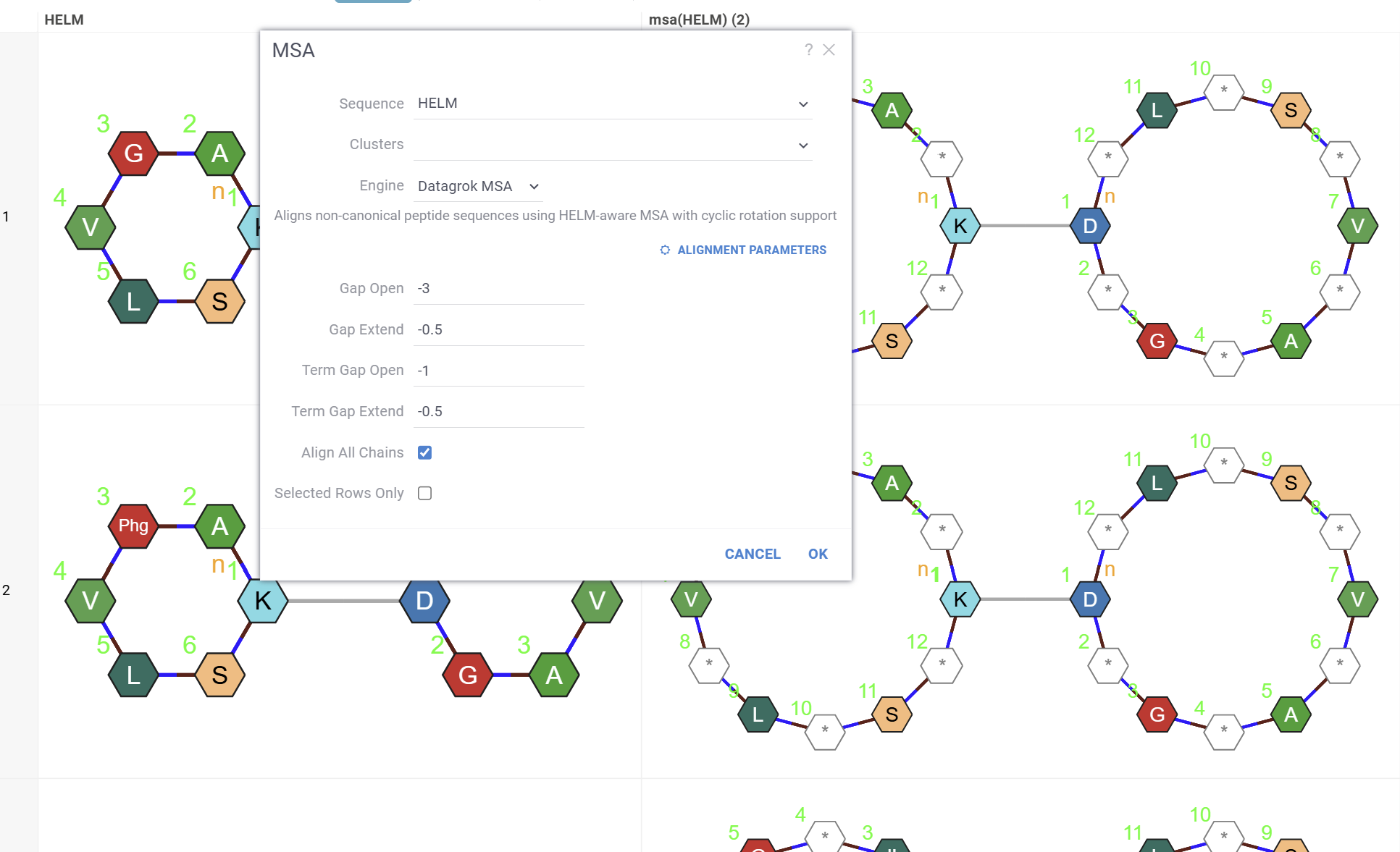
-
In the dialog, select the sequence column (Sequence). For non-canonical sequences, select an Engine (for example, Datagrok MSA or PepSeA) and adjust engine-specific parameters using the Alignment parameters button. If your data has been clustered already, you can align sequences only within the same cluster. To do so, specify a column containing clusters (Cluster).
-
Click OK to execute. A new column containing the aligned sequences is added to the table.
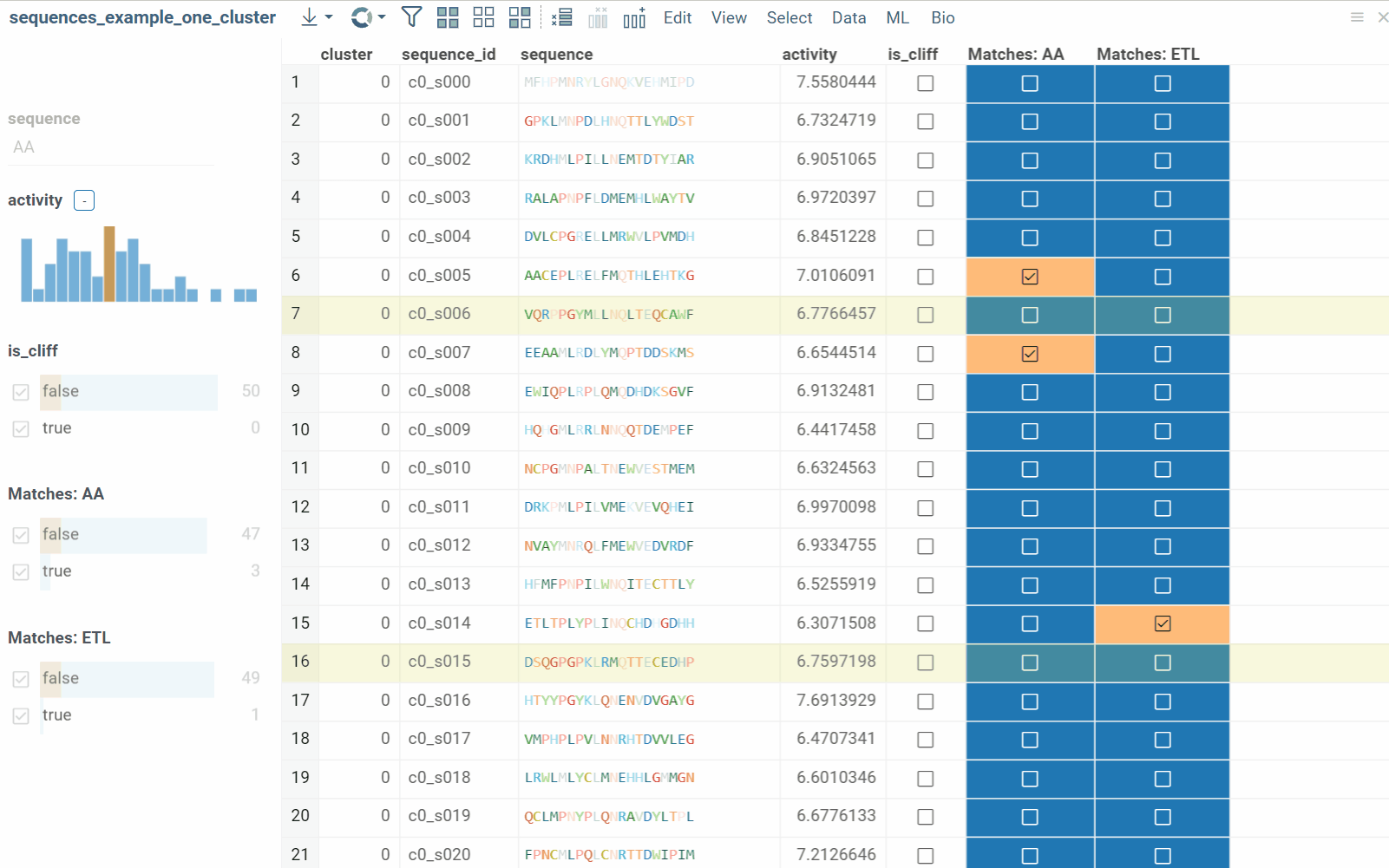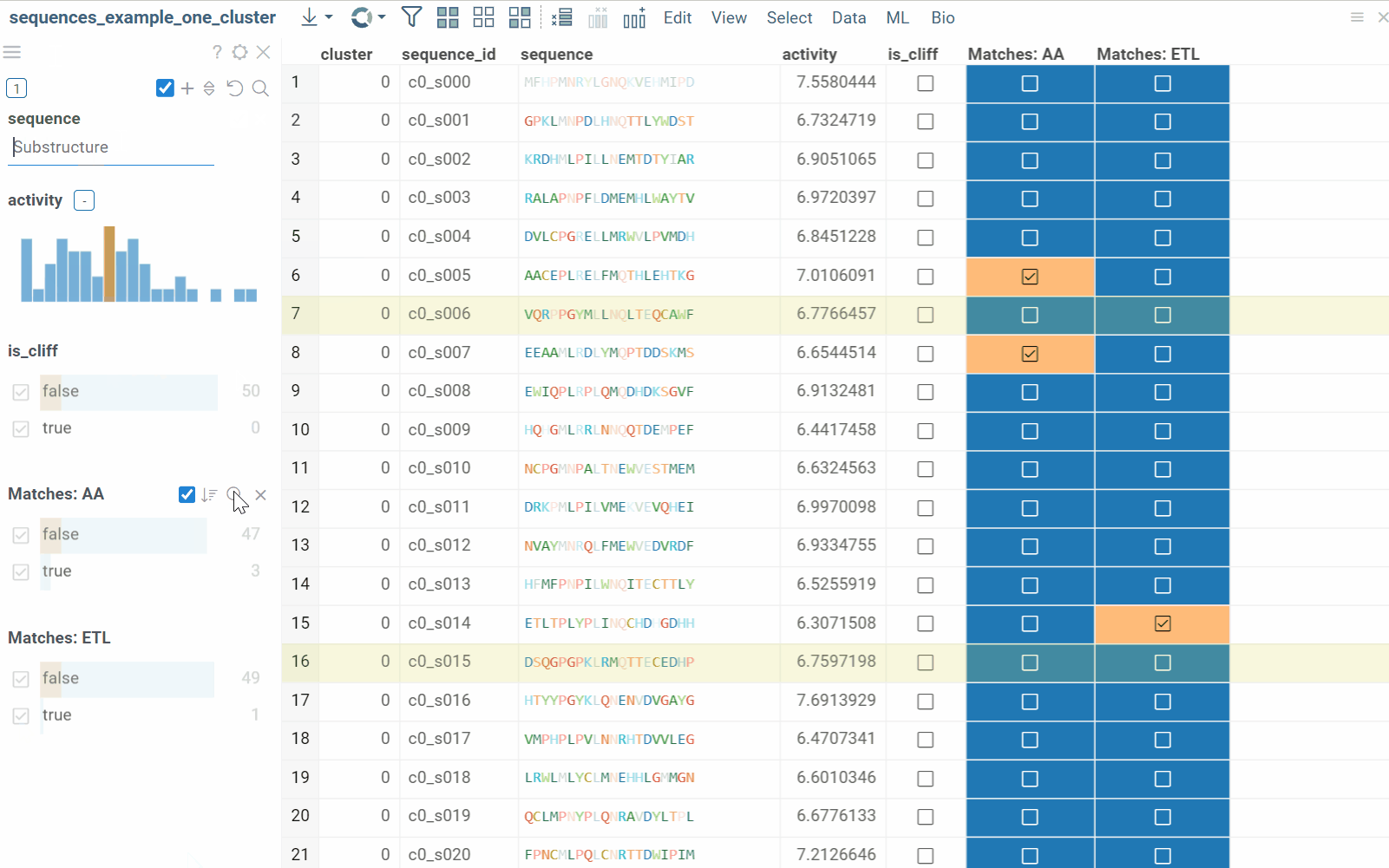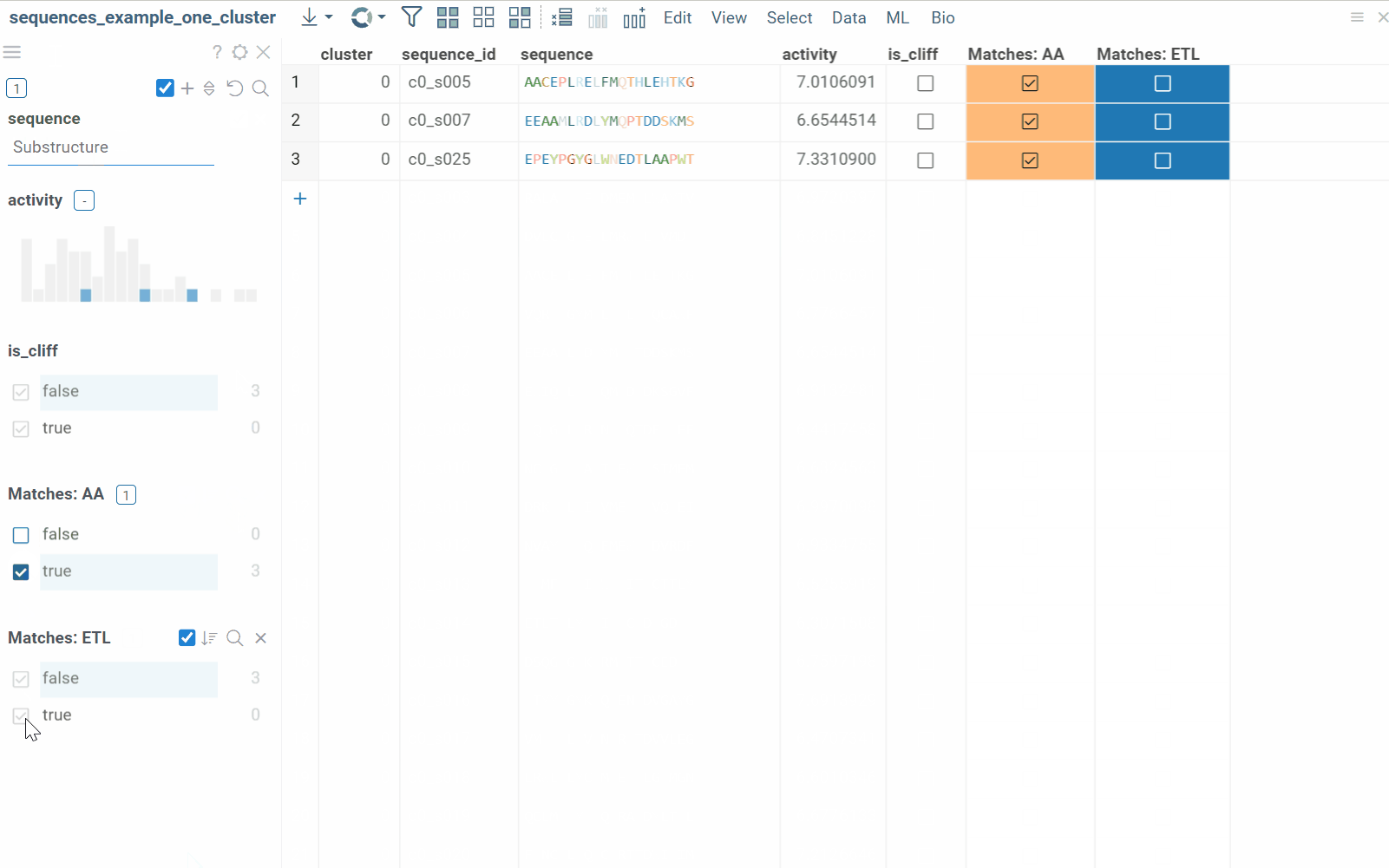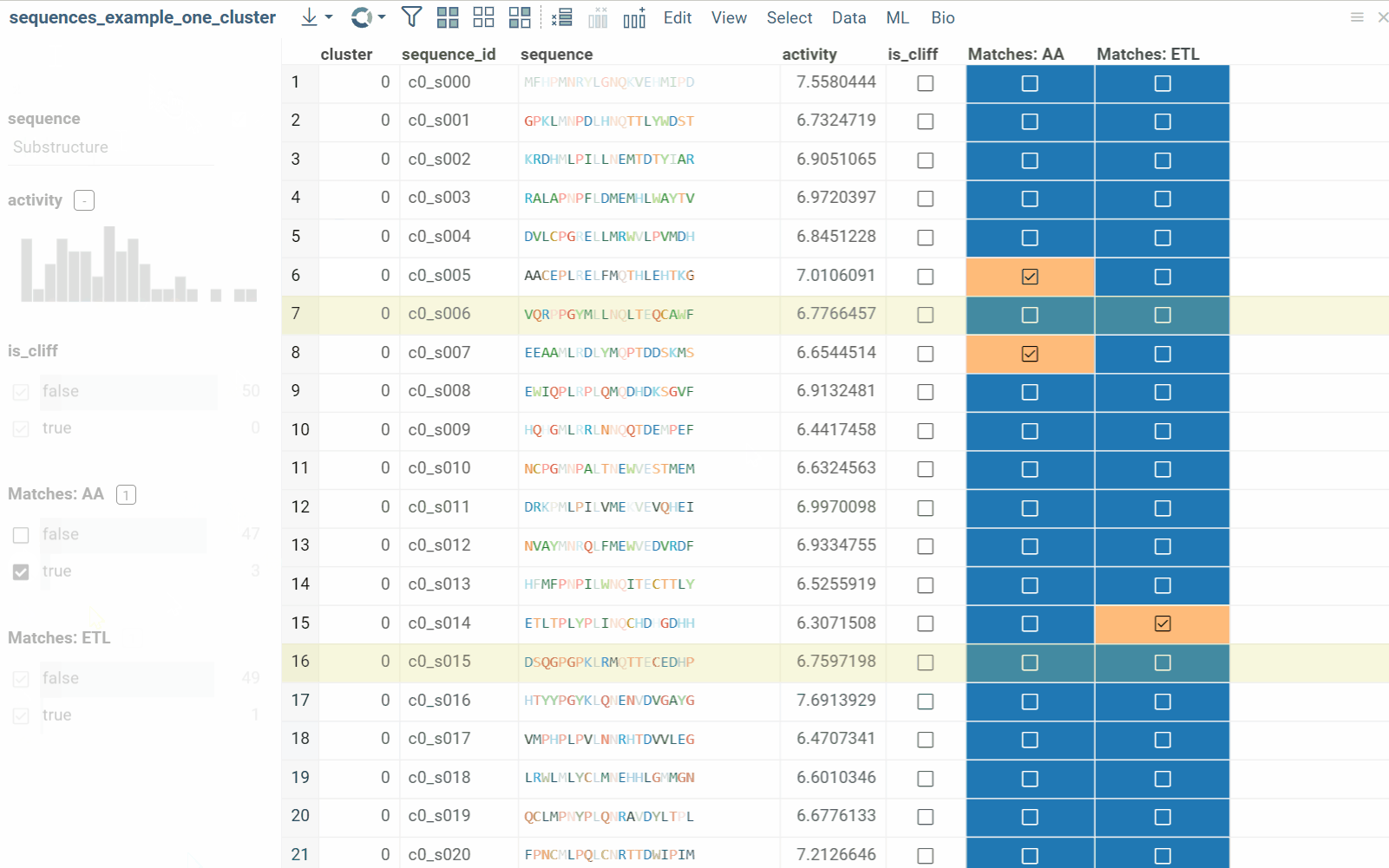
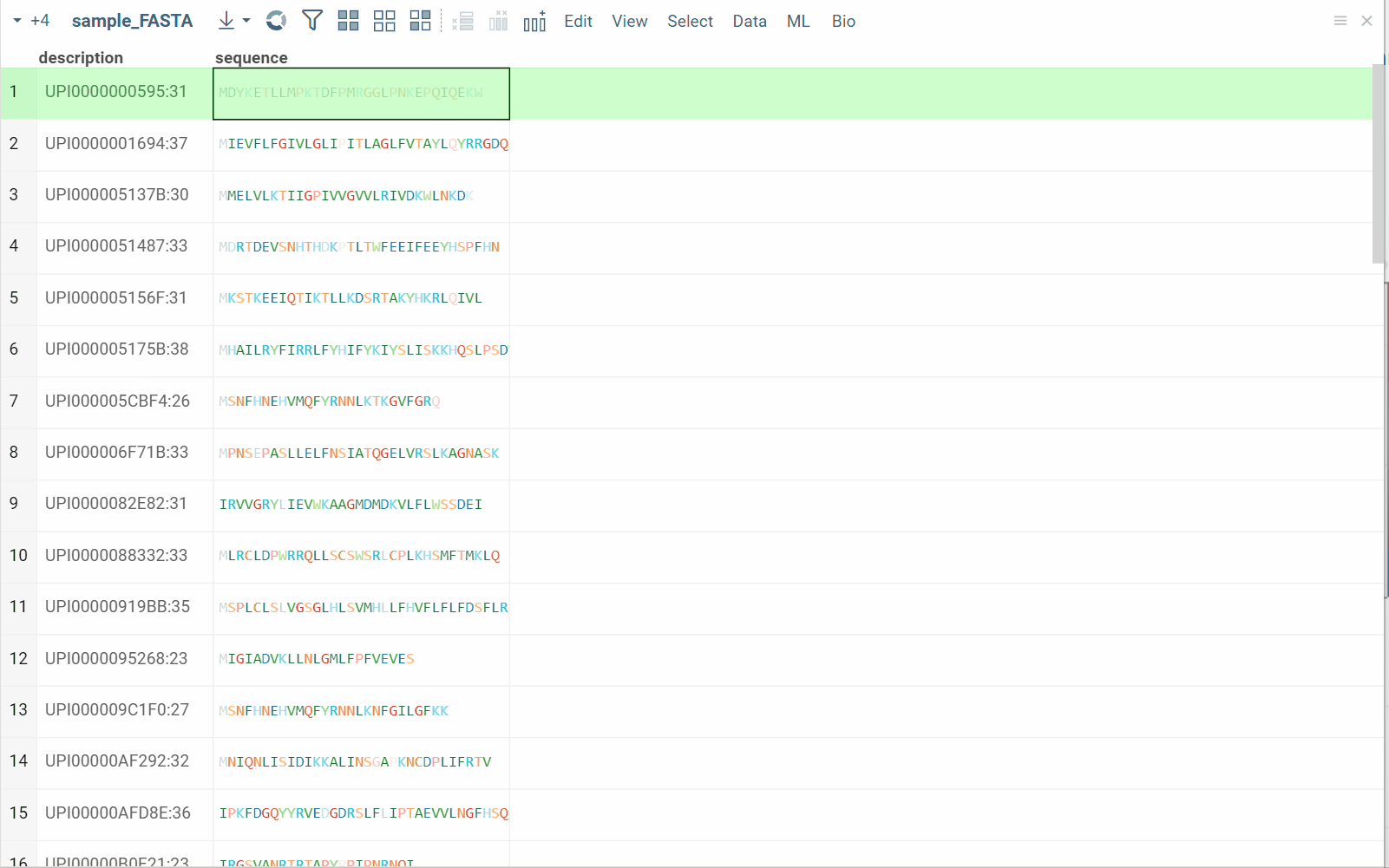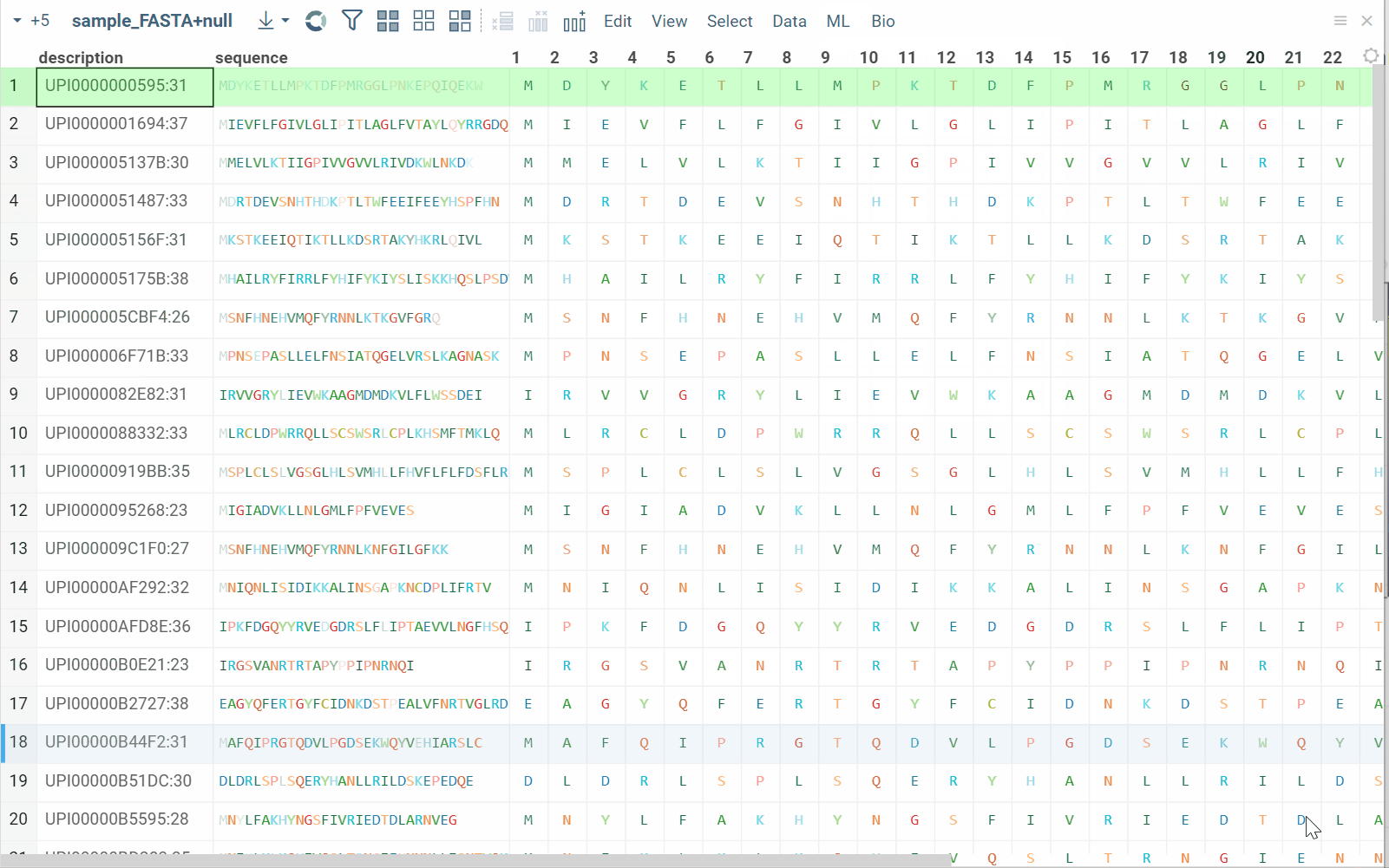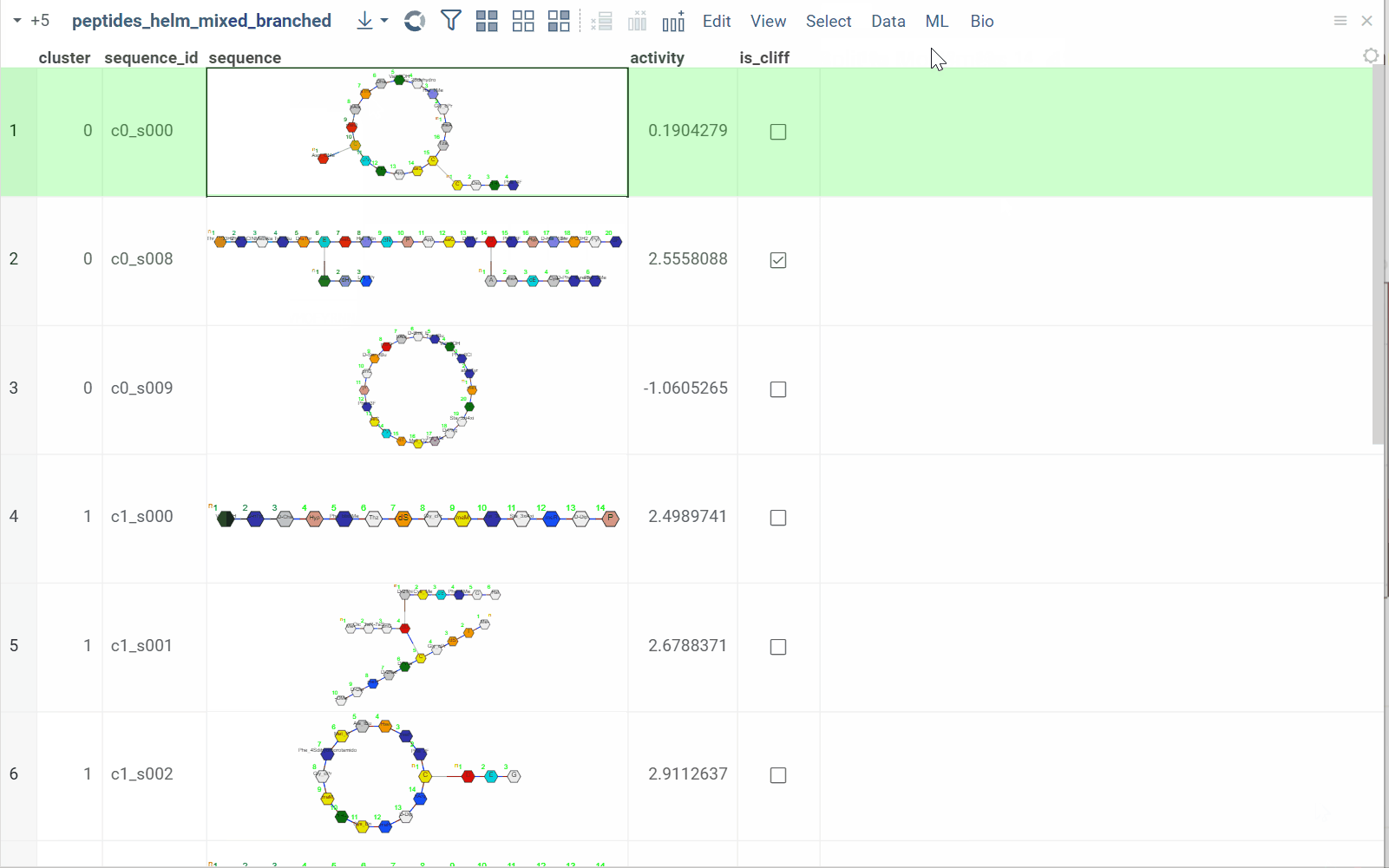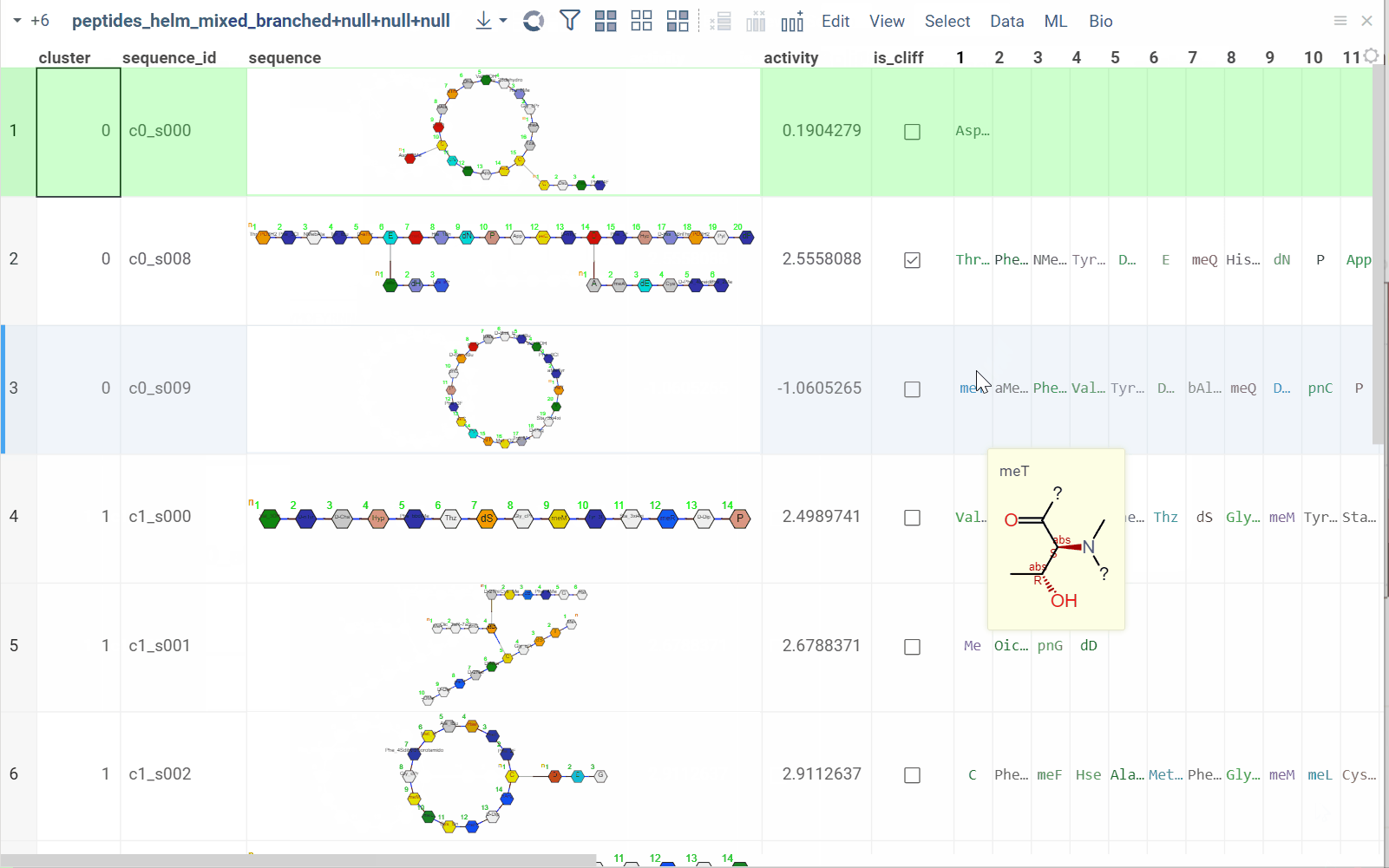
Sequence-Activity relationship analysis
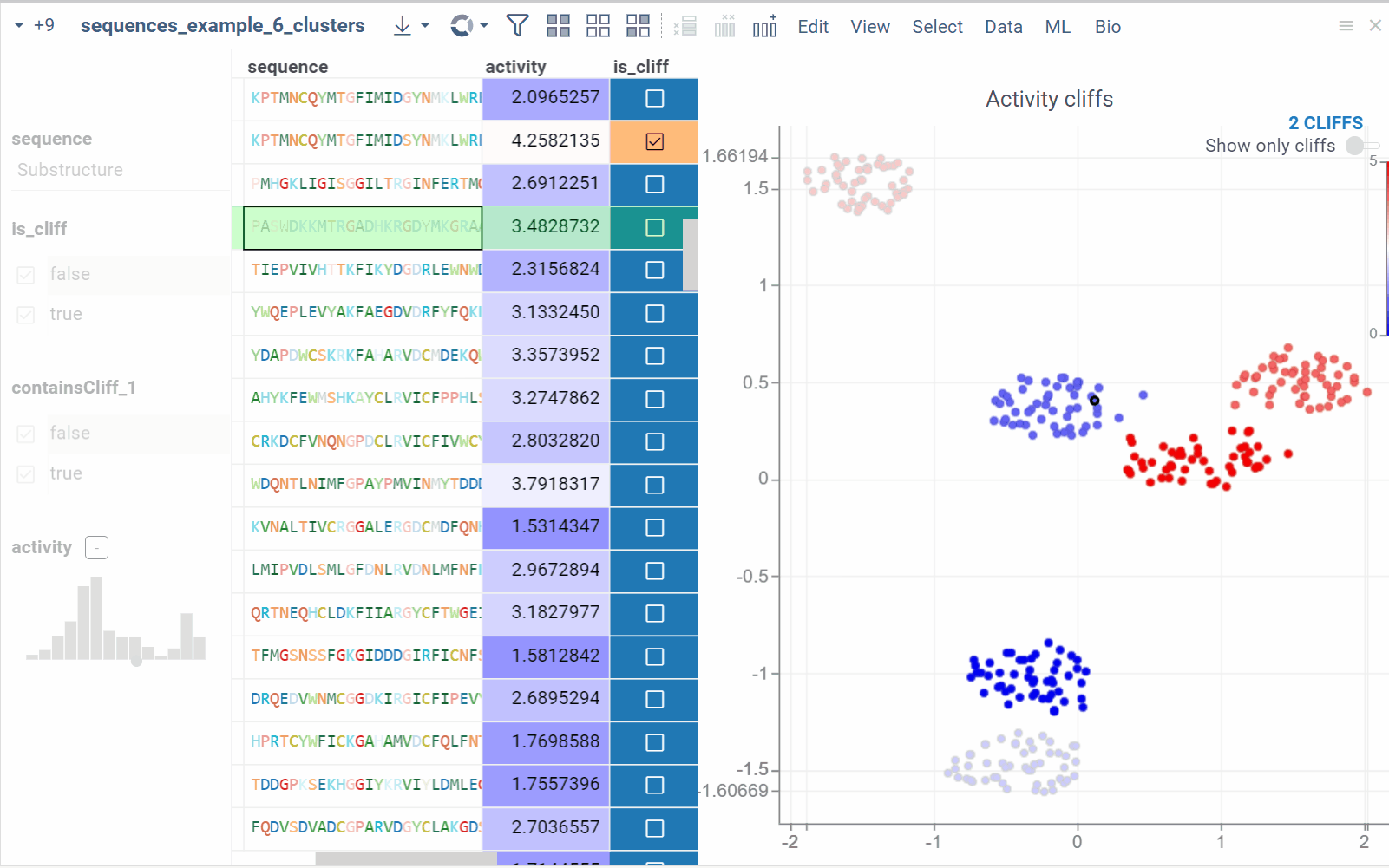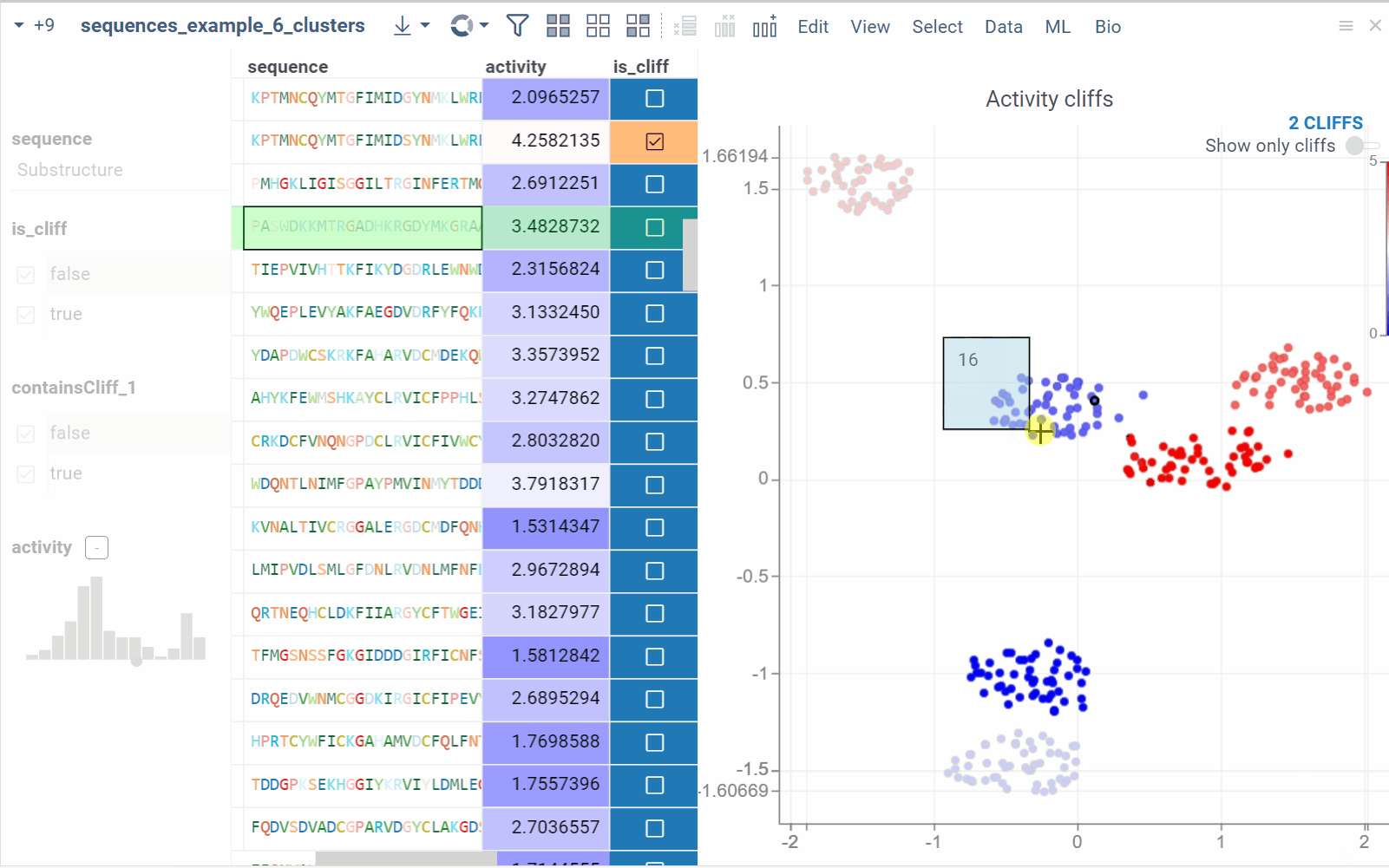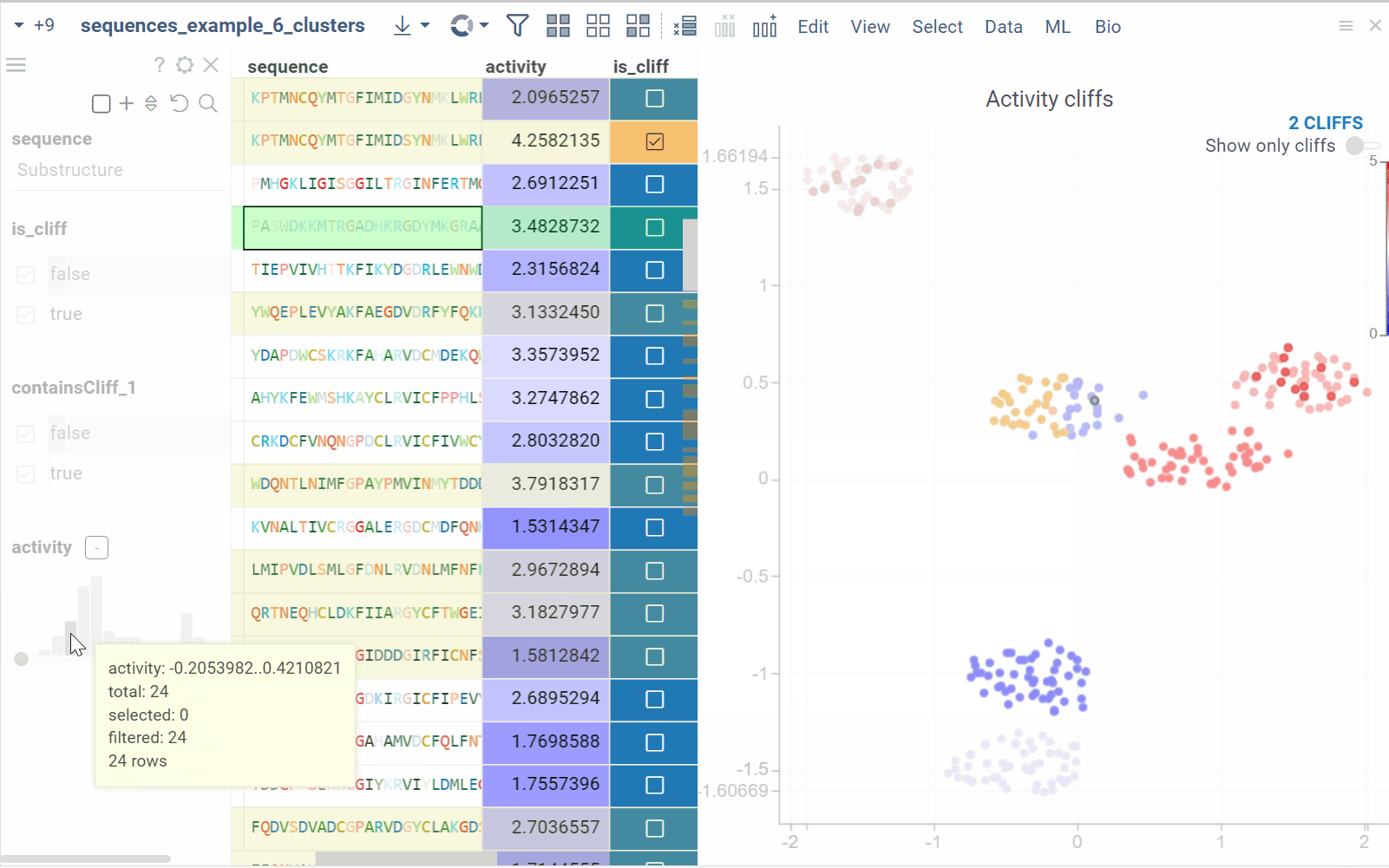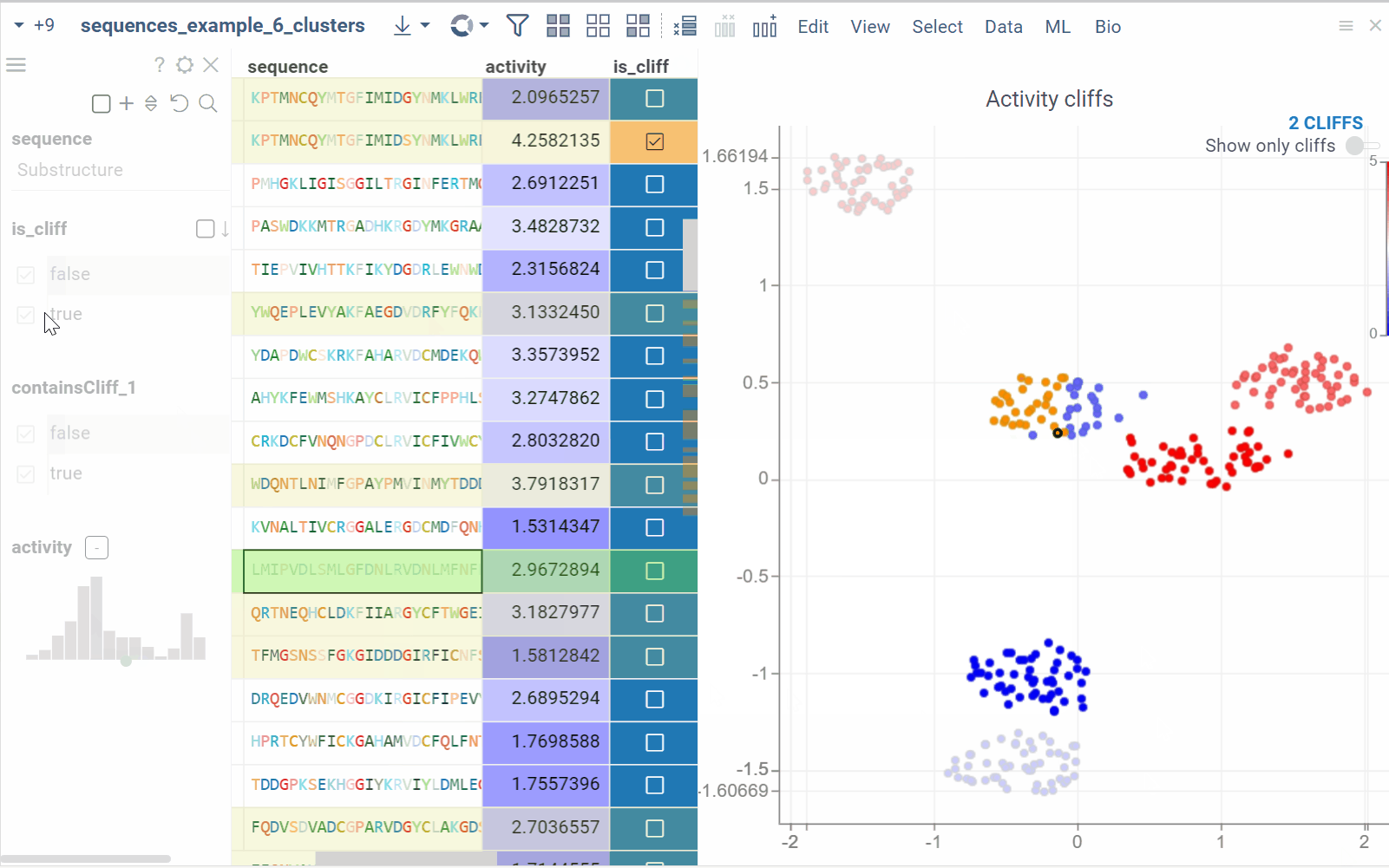
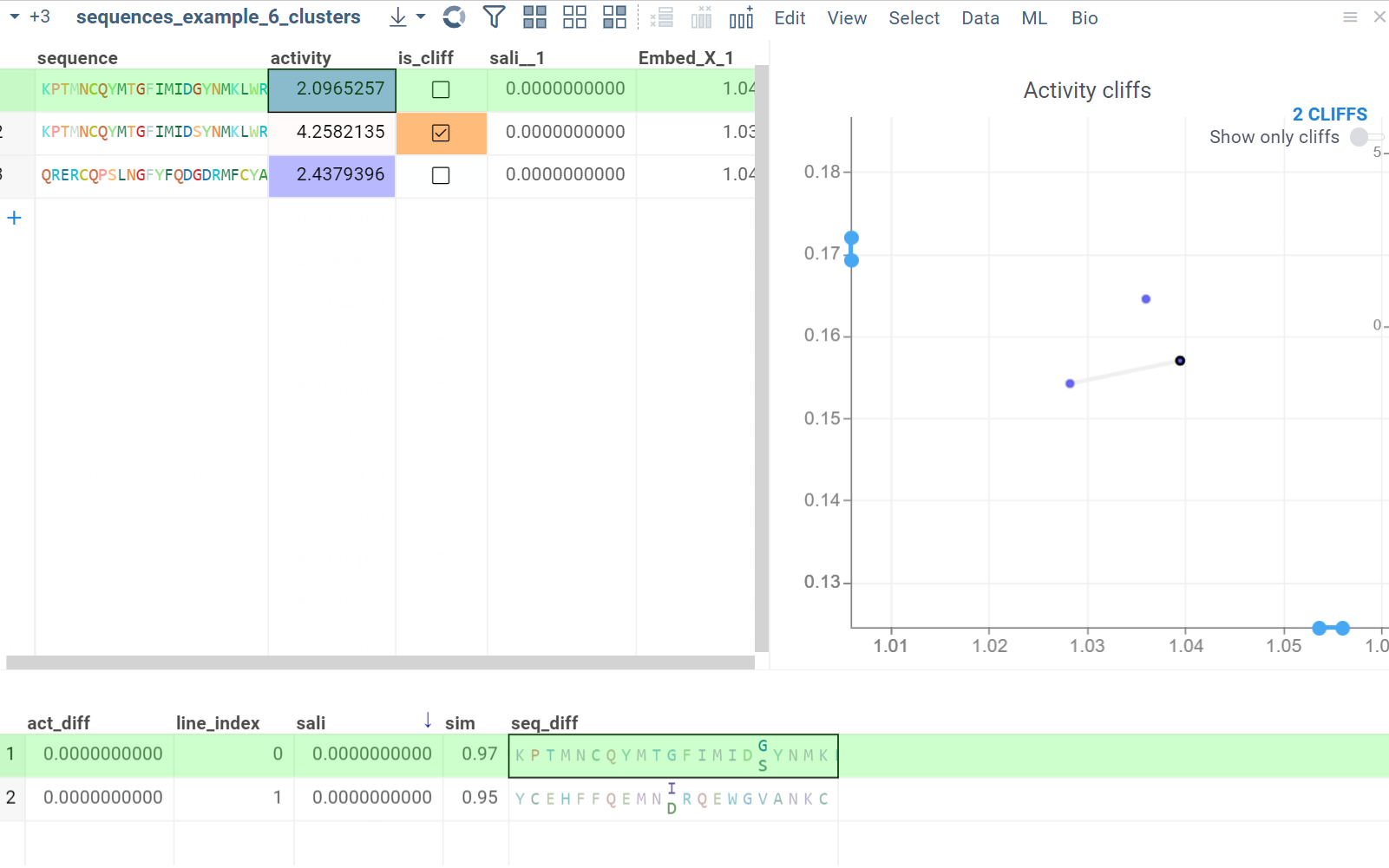
Activity cliffs
The Activity Cliffs tool in Datagrok detects and visualizes pairs of sequences with highly similar monomer composition but significantly different activity levels, known as "activity cliffs". The Activity Cliffs tool is an enhanced version of Sequence Space, specifically designed for Sequence-Activity Relationship (SAR) analysis. To run the analysis, you need a dataframe that contains peptide/DNA sequences along with numerical data representing the associated activity. For example, you can use sequences of short peptides with measured antimicrobial effects or DNA sequences with measured affinity to a specific protein.
- Activity Cliffs
- Cliff pairs
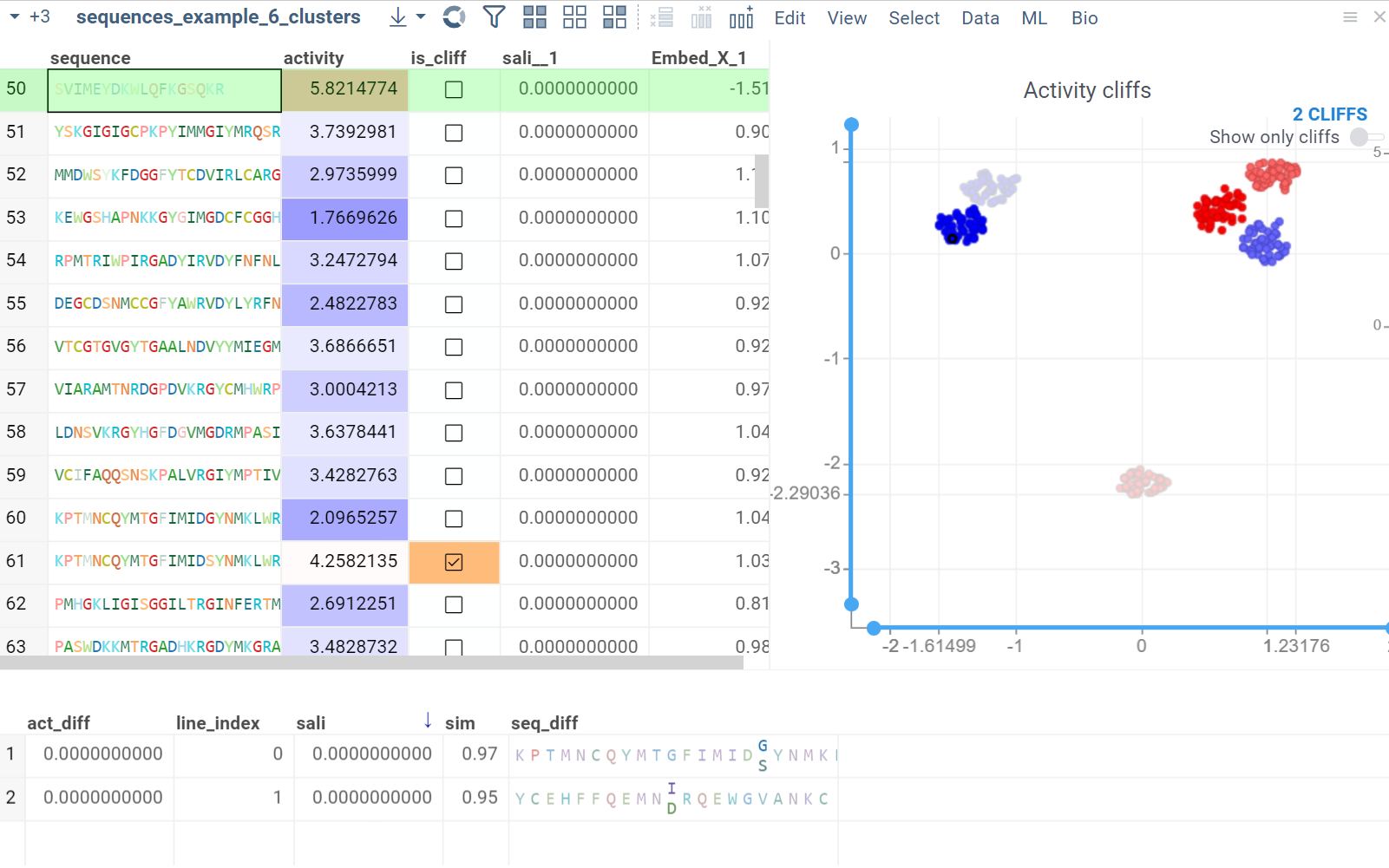
How to use
To run the activity cliffs analysis, do the following:
- In the Menu Ribbon, select Bio > Activity Cliffs... A parameter dialog opens.
- In the parameter dialog, specify the following:
- Select the source table, sequence column, and activity data column to analyze.
- Set the similarity cutoff.
- Select a dimensionality reduction algorithm and adjust its parameters using the Gear icon next to the Method control.
- Click OK to execute the analysis. A scatterplot visualization is added to the view.
- Optional. In the scatterplot, click the link with the detected number of cliffs to open an Activity Cliffs table containing all pairs of molecules identified as cliffs. The tables also has detailed information such as similarity score, activity difference score, and other data.
In the scatterplot, the marker color corresponds to the level of the sequence activity, and the size represents the maximum detected activity cliff for that sequence. The opacity of the line connecting sequence pairs corresponds to the size of the activity cliff.
To explore the sequence pairs:
- Click a sequence in the source dataframe to zoom in on the scatterplot and focus on the pair that includes the selected molecule. Hover over sequence pairs and connecting lines to see summary information about them.
- Click the line connecting sequences in the scatterplot to select a corresponding pair of sequences in the underlying dataframe and Activity Cliffs table. The reverse also applies: clicking a pair in the Activity Cliffs table updates the scatterplot and selects the corresponding rows in the underlying dataframe.
As you browse the dataset, the Context Panel updates with relevant information.
SAR for peptides
The Peptides application performs SAR analysis of peptides. The app offers the following features:
- Automatic detection of most potent monomer/positions.
- Filtering based on monomer, position, or any other attribute.
- Ability to analyze differences in activity distribution for groups of peptides.
- Dynamic calculations of statistically significant differences in activity distributions between groups.
- Analyzing the peptide space.

Additional tools and utilities
Data formats and notations
Datagrok supports a wide range of file formats and sequence notations for representing biological macromolecules.
File Formats
Sequence files:
- FASTA: Standard format for DNA, RNA, and protein sequences
- CSV/TSV: Tabular data with sequence columns
- XLSX: Excel files with biological data
- PDB: Protein Data Bank format for 3D structures
For a complete list, see supported formats.
Sequence Notations
Linear sequences:
- FASTA: Single-letter codes for natural amino acids and nucleotides (e.g.,
ACDEFGHIKLMNPQRSTVWY) - Separator-based: Custom delimiters for multi-character monomers (e.g.,
A-C-meD-E-FordA.dC.dG.dT) - HELM: Hierarchical format supporting both natural and non-natural monomers (e.g.,
PEPTIDE1{A.C.D.E.F}$$$$)
Complex structures:
- HELM: Industry standard for cyclic, branched, and conjugated structures
- BILN: Bracket-based notation for modified oligonucleotides (e.g.,
[mA].[mC].[mG].[mU]) - Polytool notation: Rules-based notation with support for custom connection rules and chemical reactions
3D structures:
- PDB: Atomic coordinates and structural information
Modalities
Datagrok handles diverse biological modalities, automatically detects them and applies appropriate analysis tools:
- DNA/RNA: Natural and modified nucleotides
- Proteins: Natural and non-natural amino acids
- Peptides: Linear, cyclic, branched, and bicyclic structures
- Oligonucleotides: With chemical modifications (phosphorothioate, 2'-OMe, LNA, etc.)
- Conjugates: Peptides with small molecules, lipids, or other chemical groups
- Antibodies: Full sequences, CDRs, and fragments
Automatic Detection
When you import data, Datagrok:
- Automatically detects sequence columns
- Determines the notation type (FASTA, HELM, separator, etc.)
- Identifies the alphabet (DNA, RNA, protein)
- Assigns appropriate semantic types
- Enables notation-specific rendering and analysis tools
This automatic detection works across all supported notations and handles mixed formats within the same dataset.
Format conversion
Datagrok provides bidirectional conversion between multiple sequence notations and molecular representations. The platform maintains structural fidelity during conversion and supports both linear and non-linear topologies.
Supported conversions:
- Sequence to sequence: HELM ↔ FASTA ↔ BILN ↔ Separator notations ↔ Polytool notation
- Sequence to molecule: HELM/FASTA/BILN/Polytool → SMILES/MOLBLOCK
- Molecule to sequence: SMILES → HELM
The conversion engine recognizes monomers from active monomer libraries and maintains topology information including:
- Cyclic structures (ring closures)
- Branching points
- Chemical modifications
- Linkers and connectors
When converting to molecular form, hovering over monomers in the sequence highlights the corresponding fragment in the resulting molecule structure, enabling easy verification of the conversion.
Also, check out a YouTube video of RDKit UGM presentation about the conversion toolkit.
Sequence notation conversion
To convert between sequence notations (e.g., HELM to FASTA, FASTA to separator format):
- In the Top Menu, select Bio > Convert > Notation...
- Select the source column containing sequences
- Choose the target notation (HELM, FASTA, Separator)
- For separator format, specify the delimiter character (e.g.,
-,.,/) - Click OK to add the converted column to your table
Sequence to SMILES conversion
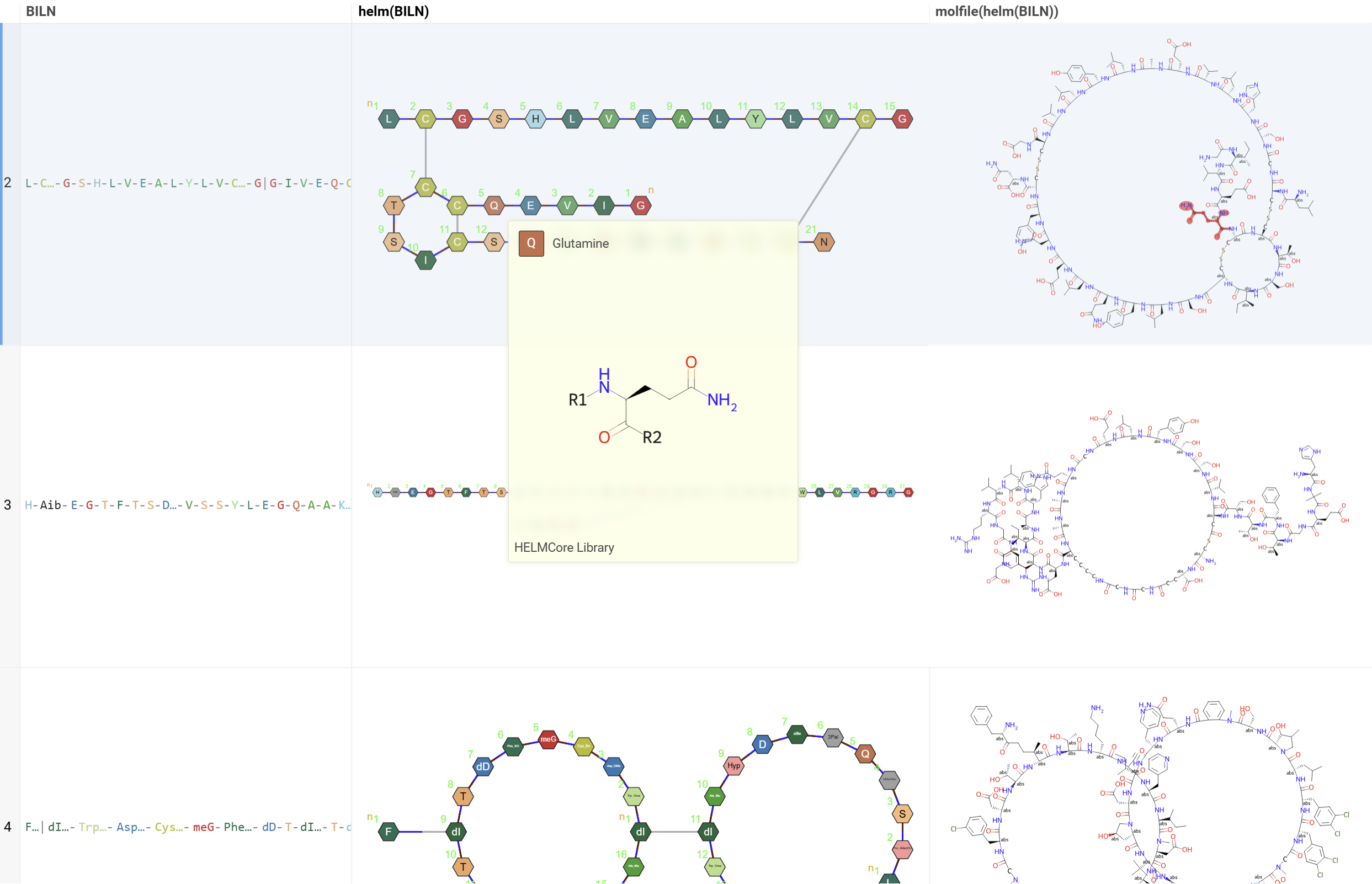
When you convert a sequence to molecular form:
- Non-linear structures (cyclic, branched) are fully supported
- The resulting molecule preserves all connections and modifications
- Hovering over sequence monomers highlights corresponding molecular fragments
- Useful for further cheminformatics analysis or molecular property calculations
SMILES to HELM conversion
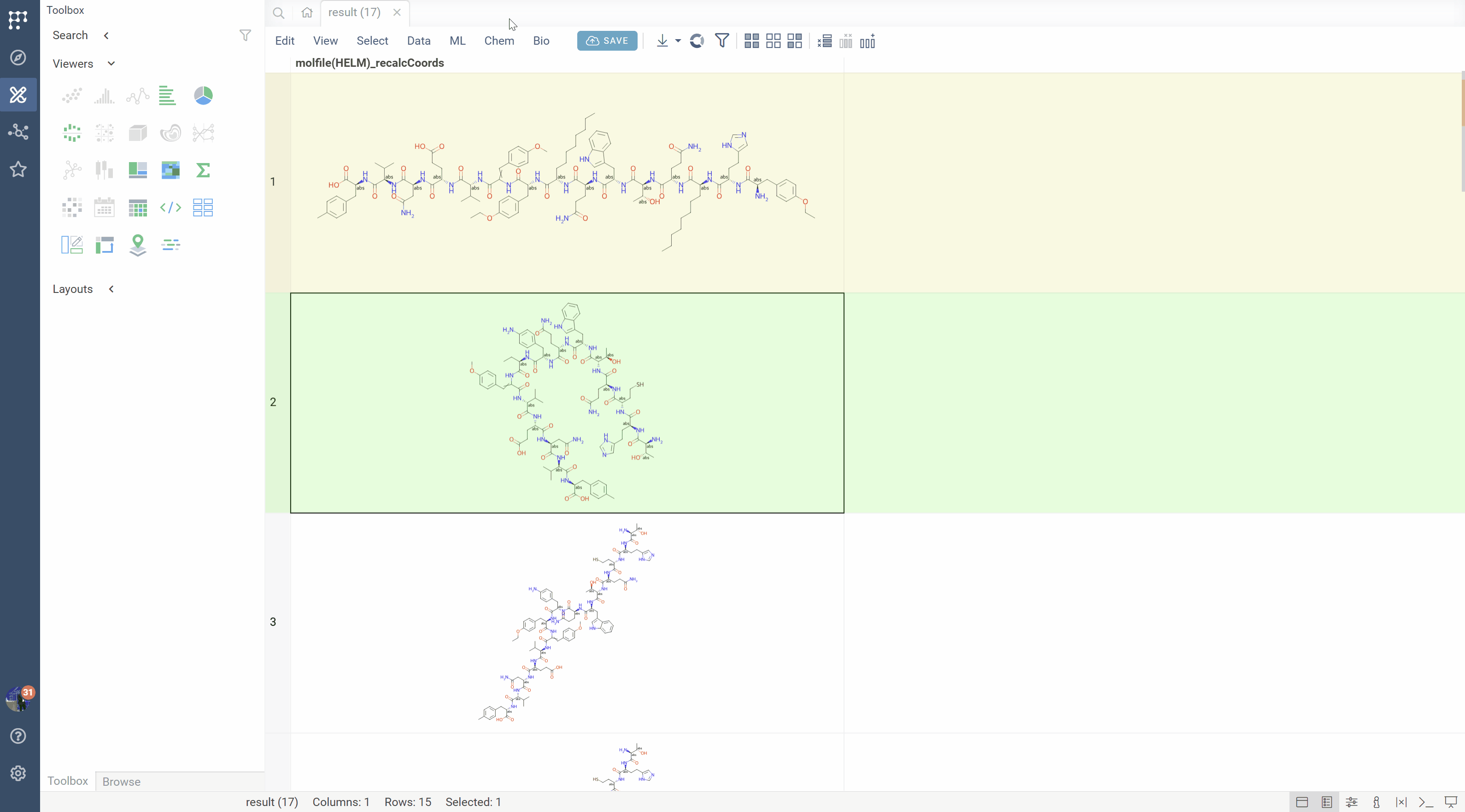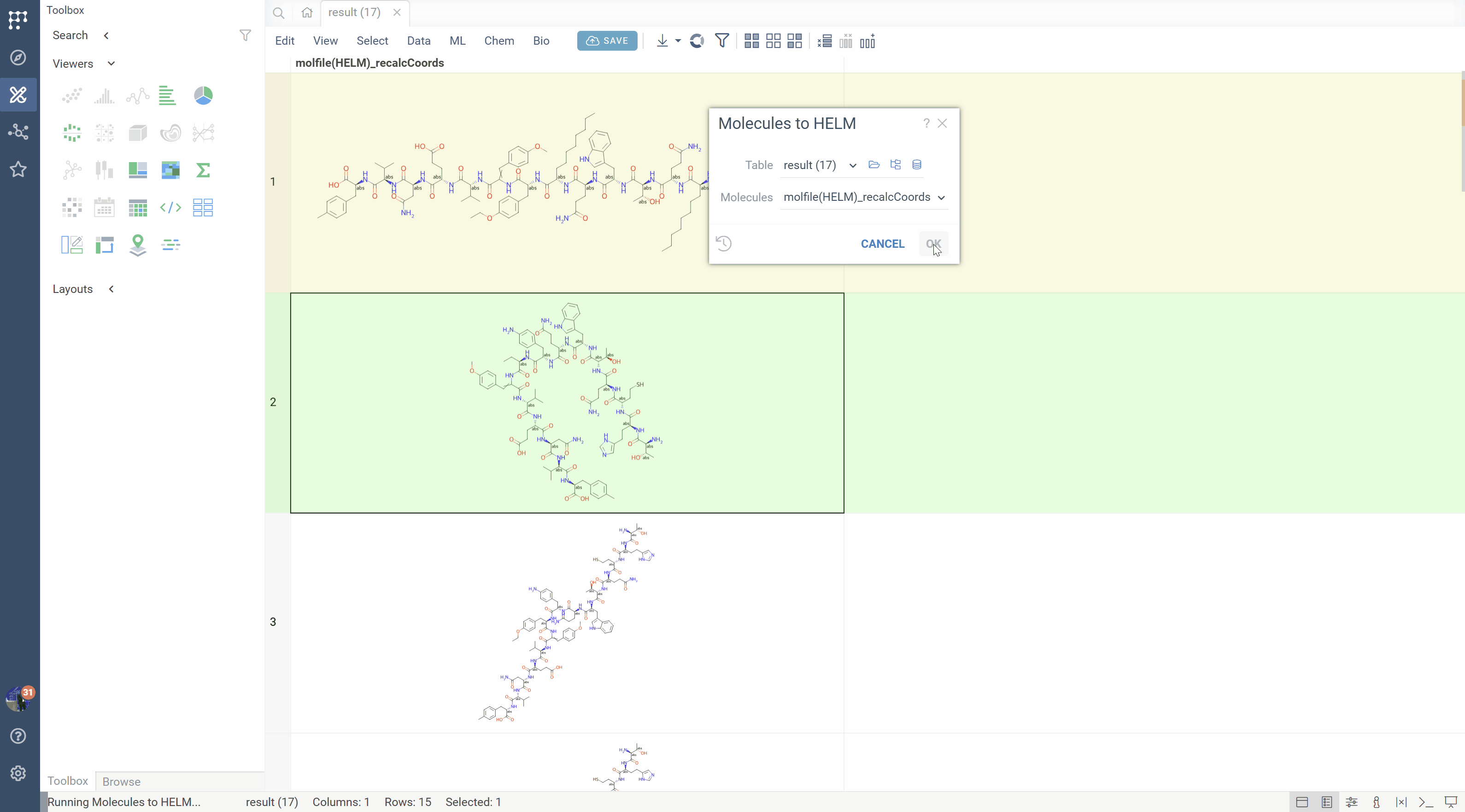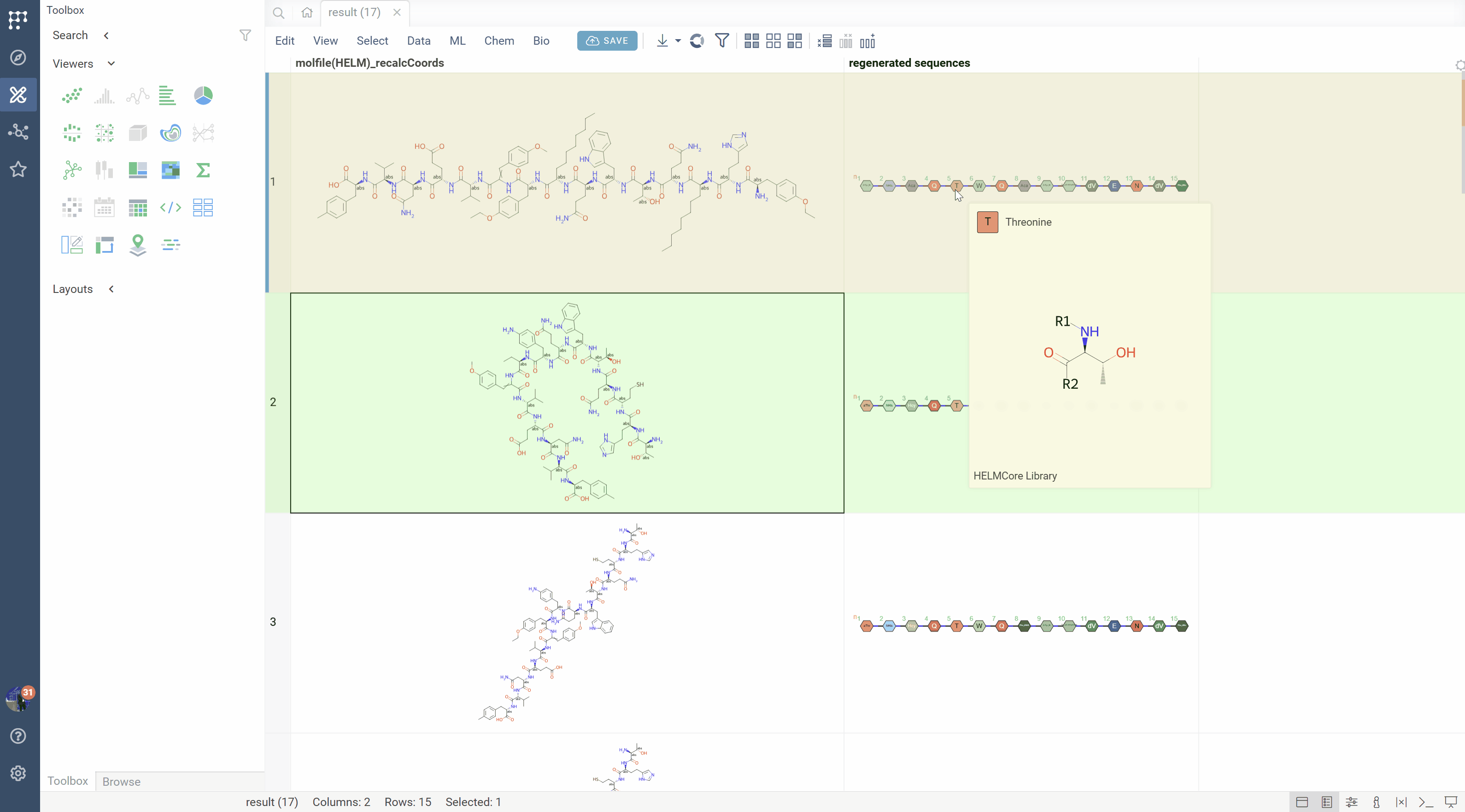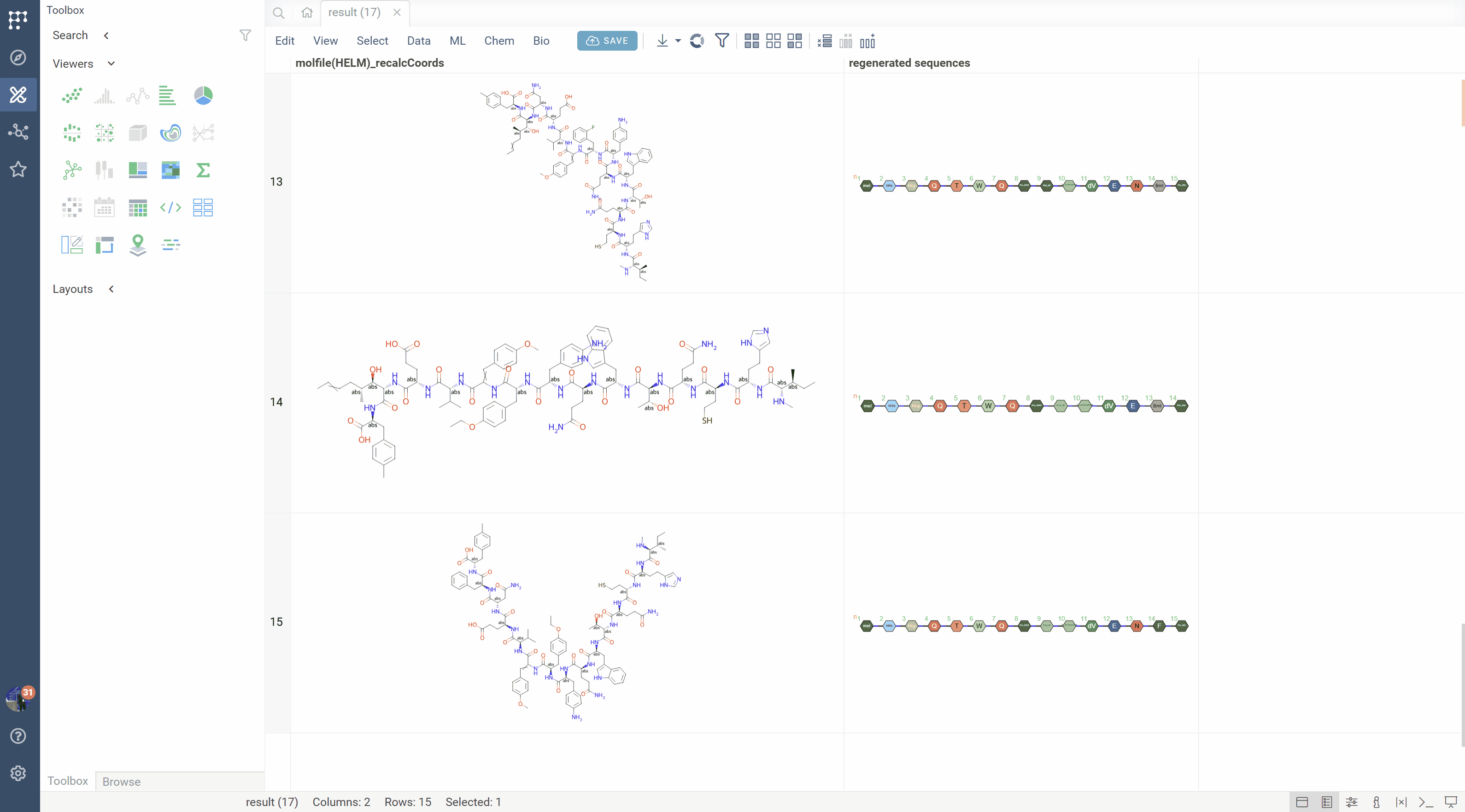
The platform can recognize monomer patterns in SMILES strings and convert them back to HELM notation:
- Matches molecular fragments against the active monomer library
- Reconstructs the sequence with proper monomer symbols
- Identifies connection patterns (backbone, side chains, modifications)
- Reports unrecognized fragments for manual review
This is particularly useful when working with peptide-like molecules from chemical databases or when integrating with traditional small molecule workflows.
Sequence manipulation and transformation
Split to monomers
You can split linear macromolecules into individual monomers, generating one column for each position in the sequence. This is useful for position-specific analysis, such as studying the effect of specific residues at particular positions.
The tool maintains position information and monomer properties, enabling downstream statistical analysis or machine learning on individual positions.
How to use
- In the Top Menu, select Bio > Transform > Split to Monomers. A dialog opens.
- In the dialog, select the sequence column and click OK to execute. New columns containing monomers are added to the table.
Get region
Extract specific regions from macromolecule sequences while preserving position annotations and labels. This is particularly useful for analyzing antibody CDRs, protein domains, or specific motifs across a dataset.
The Get Region function maintains .positionNames and .positionLabels tags for extracted regions. If a column is annotated with a .regions tag (JSON format), the input form displays predefined regions for easy selection.
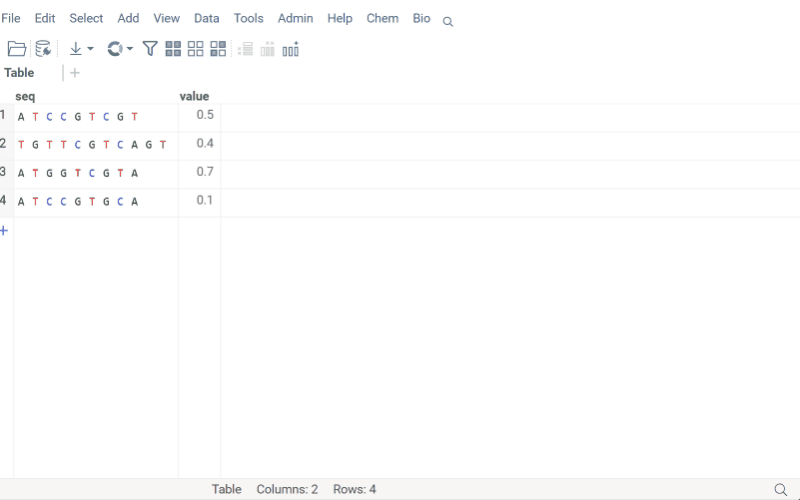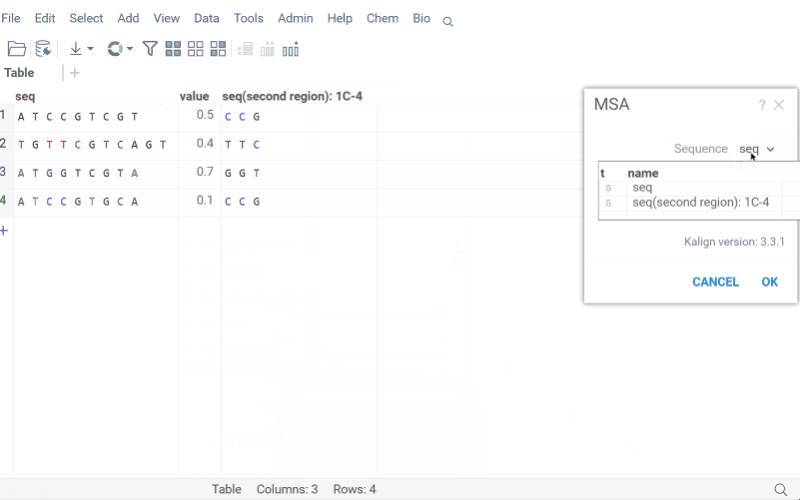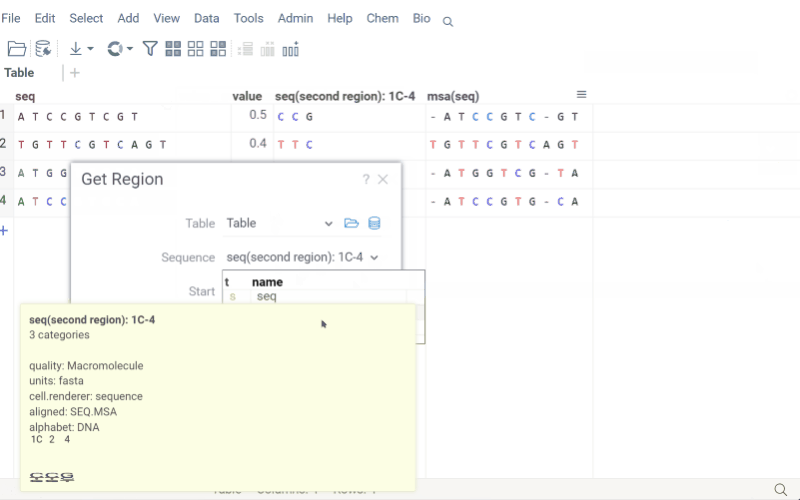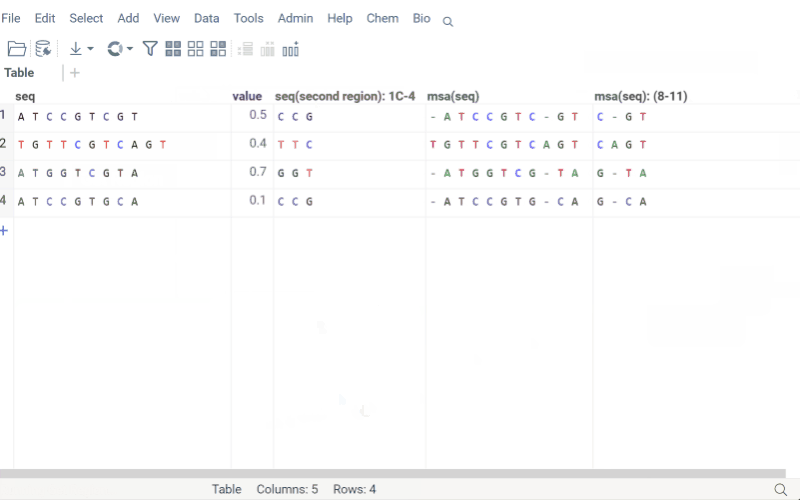
How to use
-
To call Get Region:
- Select Bio > Calculate > GetRegion. A dialog opens. In the dialog select a table and a sequence column.
- Alternatively, click on the Hamburger icon of a Macromolecule column and expand the Get Region section.
-
Fill in start and end positions of the region of interest, and name for the output column. A new column containing sequences of the region of interest is added to the table.
Convert to atomic level
Datagrok enables you to generate atomic-level structures for macromolecule sequences in HELM, FASTA, BILN or Separator notations. This bridges the gap between sequence-level and chemistry-level analysis, allowing you to:
- Perform molecular property calculations
- Analyze structures with cheminformatics tools
- Visualize 3D conformations
- Study molecular interactions
You have two options for generating atomic structures:
Option 1: Optimized 3D structures
- Converts non-linear, cyclic, and branched sequences
- Generates optimized 3D conformations using RDKit
- Suitable for structure-based analysis and visualization
- Handles complex topologies including rings and branches
Option 2: Linear representation
- Reproduces the linear form of sequences
- Useful for visual inspection and comparison
- Depicts molecules (DNA/RNA/peptides) in a more user-friendly way, without optimizing for 3D conformation
The conversion uses monomers defined in active monomer libraries. After conversion, hovering over monomers in the sequence highlights the corresponding part of the atomic structure in the molecule, enabling easy structure verification.
- Non-linear sequences
- Linear sequences
Non-linear sequences, represented in HELM or BILN notations, can be converted to atomic-level structures. The conversion process involves generating the molecular structure based on the sequence and optimizing it using RDKit.
Linear sequences, represented in any notation (HELM, FASTA, BILN, Separator), can be converted to atomic-level structures by reconstructing the linear form of the molecules. This method is particularly useful for visual inspection of linear peptide or nucleotide sequences.
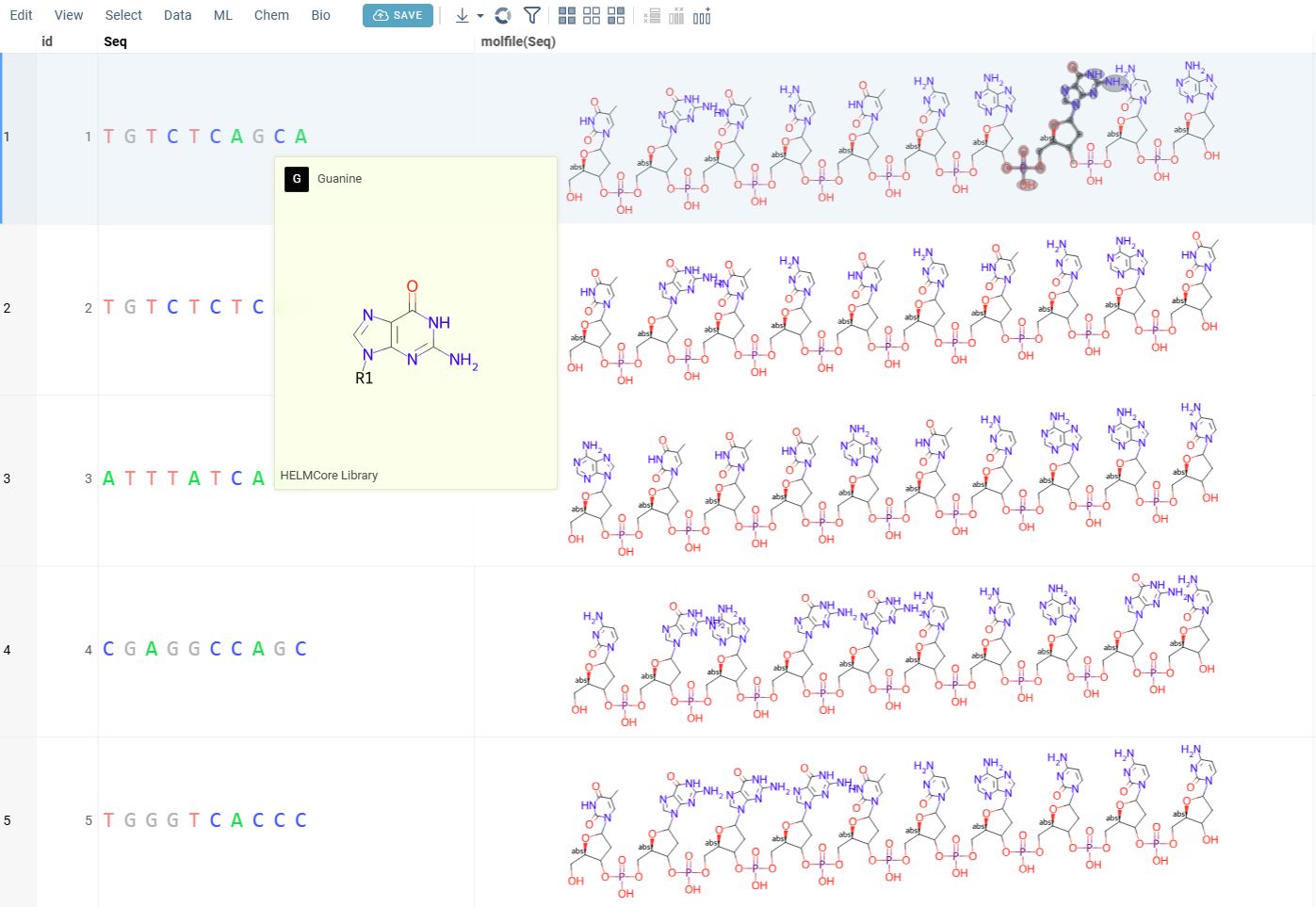
How to use
- In the Top Menu, select Bio > Convert > To Atomic Level. A dialog opens.
- In the dialog, configure:
- Sequence column: Select the column containing sequences
- Non-Linear: Choose between optimized structures or linear representation
- Click OK to execute. A new column containing atomic structures is added to the table. A Chem menu appears in the Top Menu, providing access to cheminformatics tools applicable to generated molecules.
When you click on the atomic-level structures, the Context Panel displays chemistry-related information and actions.
Polytool
Polytool is a comprehensive suite of tools for working with custom rules-based sequence notations and sequence enumeration. It provides a simplified notation system that supports both simple R-group connections and complex chemical reactions between monomers.
Key features include:
- Rules-based connection system with UI management
- Support for reaction-based chemistry (e.g., click reactions)
- Sequence enumeration for library generation
- Conversion to atomic structures and other notations
To learn more, see the Polytool documentation.
Oligo Toolkit
The Oligo Toolkit is a collection of tools helping you to work with oligonucleotide sequences. To learn more and how to use, see the OligoToolkit page.
Customizing and extending the platform
Datagrok is a highly flexible platform that can be tailored to meet your specific needs and requirements. With its comprehensive set of functions and scripting capabilities, you can customize and enhance any aspect of the platform to suit your biological data needs.
For instance, you can add new data formats, custom libraries, apply custom models, or perform advanced calculations and analyses using powerful bioinformatics libraries like Biopython, Bioconductor, ScanPy, and others.
You can also add or change UI elements, create custom connectors, menus, context actions, and more. You can even develop entire applications on top of the platform or customize any existing open-source plugins.
Learn more about extending and customizing Datagrok.
Resources
- Demo app
- Community:
- Videos: